7 장 R에서의 프로그래밍
R 언어는 S 언어에 기반을 두고 있다. S 언어의 개발에 주도적인 역할을 했던 Richard Becker, John Chambers와 Allan Wilks는 Becker and Wilks (1988) 에서 S는 데이터 분석 및 그래픽스를 위한 언어이자 대화형 프로그래밍 환경이며, S 환경의 주된 목적은 훌륭한 데이터 분석을 가능하게 하는 것이라 하였다. S 언어는 프로그래밍 언어로서 필요한 모든 특징을 갖고 있어서 어떤 형태의 데이터 분석이나 그래프 분석도 사용자가 작성한 프로그램으로 수행이 가능하다. 비록 S 개발자들에게 ’데이터 분석’이란 통계적 데이터 분석만을 의미한 것은 아니었으나, 가장 활발하게 S를 사용한 집단은 바로 통계학자들이라 할 수 있다.
S 언어의 특징을 고스란히 갖고 있는 R 언어 또한 매우 뛰어난 프로그래밍 언어이다. 최근 들어 R이 통계학 이외의 분야에서도 ’데이터를 기반으로 하는 다양한 프로그래밍’의 목적으로 활발하게 사용되고 있는데, Wickham (2019) 와 Venables and Ripley (2000) 이 R을 본격적인 프로그래밍 도구로 사용하고 있는 프로그래머들에게는 큰 도움이 될 것이다.
이 장에서는 R의 기본적인 프로그래밍 기법 중 통계분석 과정에서 자주 사용되는 기법들을 주로 살펴보고자 한다. R 언어를 이용하여 효과적인 프로그램을 작성하기 위해서는 반드시 R 언어의 문법에 익숙해져야 하는데, 이미 우리는 데이터 준비하기와 데이터 다루기의 관점에서 R 언어 문법의 많은 부분을 다루었다. 프로그래밍의 관점에서 본다면 약간 산만한 방식으로 소개된 것이지만 통계분석의 관점에서는 체계적인 방식이라고 본다. 이제 R 언어의 가장 기본적인 개념으로서 다음 용어의 의미를 간단하게 살펴보자.
표현식(Expression)
객체(Object)
함수(Function)
R 프로그램은 일련의 표현식으로 이루어져 있다. 특정 객체에 데이터를 할당하는 문장, 조건을 비교하는 문장, 산술 표현식 등 지금까지 우리가 사용한 R 명령문이 모두 표현식이 된다. 이러한 표현식은 모두 객체와 함수로 이루어져 있으며, 새로운 줄 또는 세미콜론으로 분리가 된다.
R 프로그램은 객체를 기본 요소로 하고 있다. 지금까지 우리가 알고 있는 객체는 벡터, 행렬, 데이터 프레임, 리스트 등 모두 데이터를 담고 있는 객체들이다. 그러나 R에서는 모든 것이 객체라 할 수 있다. 함수와 표현식도 객체이다.
함수란 인수 혹은 변수라고 불리는 객체를 입력시키면 결과물 객체를 생성시키는 또 다른 R의 객체이다. R에서 수행되는 거의 모든 작업은 함수를 통해서 이루어진다.
지금까지 우리가 살펴본 R 프로그램의 수행 방식은 첫 줄부터 시작하여 한 줄씩 내려가며 모든 표현식을 차례로 실행하는 것이었다. 그러나 경우에 따라서는 이러한 수행 방식으로는 해결하기에 매우 불편한 문제들도 있을 수 있다. 예를 들어 어떤 조건이 만족되어야만 실행을 시켜야 하는 표현식이 있을 수 있고, 몇 번을 반복하여 실행시켜야 하는 표현식도 있을 수 있다. 이와 같이 프로세스의 흐름을 조절해야 하는 경우 사용할 수 있는 기법에 대해서 살펴보도록 하자. 또한 R의 큰 장점 중 하나는 바로 사용자 스스로 함수를 정의하여 사용할 수 있다는 것이다. 함수의 정의 과정 및 사용 방법에 대해서도 알아보도록 하자.
7.1 사용자 정의 함수
R의 큰 장점 중 하나가 바로 사용자가 함수를 정의해서 사용할 수 있다는 것이다. 사용자가 필요한 함수를 스스로 만들어 사용할 수 있기 때문에 전체적으로 프로그램이 상당히 간결하게 작성될 수 있으며, 분석 절차가 훨씬 더 효율적이 될 수 있다.
7.1.1 함수의 정의
함수를 정의하는 일반적인 방법은 다음과 같다.
my_func <- function(arg1, arg2, ...) {
표현식
}my_func는 사용자가 정의한 함수의 이름이고, arg1, arg2 등은 함수의 변수 이름을 나타내는 것이다.
중괄호에 포함되어 있는 표현식은 함수에 입력된 변수들을 사용하여 사용자가 원하는 연산을 수행하도록 작성된 R 표현식이다.
표현식은 일반적으로 중괄호에 싸여 있는데 표현식이 단 한 줄인 경우에는 굳이 중괄호를 사용하지 않아도 된다. 예를 들어 다음에 정의된 함수 f1()과 f2()는 동일한 것으로, 입력된 두 변수의 합을 계산한다.
7.1.2 변수
함수에 입력되는 변수는 크게 두 가지 종류로 구분된다. 하나는 연산 대상이 되는 데이터이고, 다른 하나는 연산과 관련된 세부 옵션이다. 일반적으로 함수의 첫 번째 변수는 데이터가 되며, 이어서 필요한 세부 옵션들이 그 이후의 변수로 입력된다.
예를 들어 표본 자료를 사용하여 모평균에 대한 신뢰구간을 계산하는 함수를 정의해 보자. 모집단의 표준편차를 추정해야 되며, 정규분포를 이용할 수 있는 상황이라고 가정하자. 이 경우 표본 자료가 첫 번째 변수가 되고, 신뢰구간의 신뢰수준이 두 번째 변수로 입력되어야 한다. 세부 옵션과 관련된 변수의 경우에는 디폴트 값이 주어지는 것이 일반적인 상황인데, 신뢰구간의 경우에도 신뢰수준의 디폴트 값은 0.95로 잡을 수 있다.
CI_mean <- function(x, conf = 0.95){
m <- mean(x)
se <- sd(x)/sqrt(length(x))
alpha <- 1 - conf
c(m - qnorm(1 - alpha/2) * se, m + qnorm(1 - alpha/2) * se)
}함수 qnorm()은 정규분포에서 분위수를 계산하는 함수이다.
p에 원하는 확률 값을 입력하면 그 값에 해당하는 분위수를 출력하며,
평균과 표준편차는 변수 mean과 sd로 지정할 수 있는데, 디폴트는 mean = 0, sd = 1인 표준정규분포이다.
함수 CI_mean()에서 디폴트 값이 부여된 변수인 conf는 함수를 실행할 때 생략이 가능한데, 생략되면 디폴트 값인 0.95가 지정된다.
함수 rnorm()은 정규분포에서 난수를 발생시키는 함수이다.
난수의 개수는 n에 지정을 하며,
평균과 표준편차는 변수 mean과 sd로 지정할 수 있는데, 디폴트는 mean = 0, sd = 1인 표준정규분포이다.
함수 set.seed()는 난수 발생의 seed를 지정하는 것으로 위와 동일한 결과를 볼 수 있도록 사용하였다.
벡터 x에는 정규분포에서 임의로 추출한 100개의 표본 자료가 입력되어 있으며,
이것을 우리가 정의한 함수 CI_mean()에 입력한 결과, 디폴트인 95% 신뢰구간이 계산되었다.
만일 디폴트로 입력된 옵션 값을 수정하고자 한다면, 해당 변수에 직접 값을 지정하면 된다.
동일한 자료에 대하여 90% 신뢰구간을 구해 보자. 두 번째 변수 conf에 0.9를 입력하면 된다.
함수의 변수를 지정할 때 마지막 변수 다음에 생략 부호(...)를 추가하는 경우가 있는데,
이 생략 부호는 사실 특별한 기능을 갖고 있는 또 다른 변수이다.
기존의 다른 함수를 이용하여 사용자가 자신의 함수를 정의하는 경우가 많이 있는데,
생략 부호를 변수의 리스트에 추가하면 기존의 다른 함수에 적용되는 부가적인 변수들을 마치 자신이 정의한 함수의 변수처럼 사용할 수 있다.
함수 CI_mean() 안에는 함수 mean()과 sd()가 있는데, 이 함수들은 데이터에 NA가 포함되어 있으면, 그 결과도 NA로 출력된다.
이 경우 옵션 na.rm = TRUE를 포함하면 NA를 제외한 나머지 데이터를 대상으로 계산이 진행된다.
함수 CI_mean()에 벡터 x에 NA를 하나 추가한 벡터 y를 입력하고, 그 실행결과를 살펴보자.
함수 CI_mean()에는 변수 na.rm이 선언되지 않은 변수이기 때문에 사용할 수 없음을 알 수 있다.
이러한 문제를 해결하기 위하여 함수 CI_mean()에 생략부호인 변수 ...을 추가하고,
함수 안에 있는 또 다른 함수인 mean()과 sd()에도 변수 ...을 추가한 함수 CI_mean_dot()를 정의해 보자.
이 경우 함수 CI_mean_dot()에 추가한 옵션은 바로 함수 mean()과 sd()로 전달되어 실행된다.
CI_mean_dot <- function(x, conf = 0.95, ...){
m <- mean(x, ...)
se <- sd(x, ...)/sqrt(sum(!is.na(x)))
alpha <- 1 - conf
c(m - qnorm(1 - alpha/2) * se, m + qnorm(1 - alpha/2) * se)
}함수 안에서 정의되는 객체 se의 분모에 표본의 개수에서 NA의 개수를 제외하기 위해 sum(!is.na(x))을 사용하였다.
벡터 y와 옵션 na.rm = TRUE를 함수 CI_mean_dot()에 입력한 결과는 벡터 y에서 NA를 제외한 벡터 x의 신뢰구간인 CI_mean(x)와 동일하게 나왔다.
생략 부호 변수 ...에 대한 다른 예제를 살펴보자.
아래에 정의된 함수 my_plot()은 두 벡터를 받아들여 함수 mean()과 sd()로 표준화를 실시한 후 함수 geom_point()로 산점도를 작성하고 있다.
함수 my_plot()에는 명시적으로 선언된 변수가 x와 y 두 개뿐이지만,
생략 부호가 추가되어 있어서, 함수 geom_point()에 color 혹은 shape 등의 시각적 요소들을 함수 my_plot()의 변수처럼 사용할 수 있다.
my_plot <- function(x, y, ...){
z_x <- (x - mean(x))/sd(x)
z_y <- (y - mean(y))/sd(y)
ggplot(tibble(x = z_x, y = z_y)) +
geom_point(aes(x, y), ...)
}예제로 함수 my_plot()을 사용하여 데이터 프레임 cars의 두 변수 speed와 dist를 표준화 시킨 후 산점도를 작성해 보자. 기호는 빨간 원으로 하자.
작성된 그래프는 그림 7.1 에서 볼 수 있다.
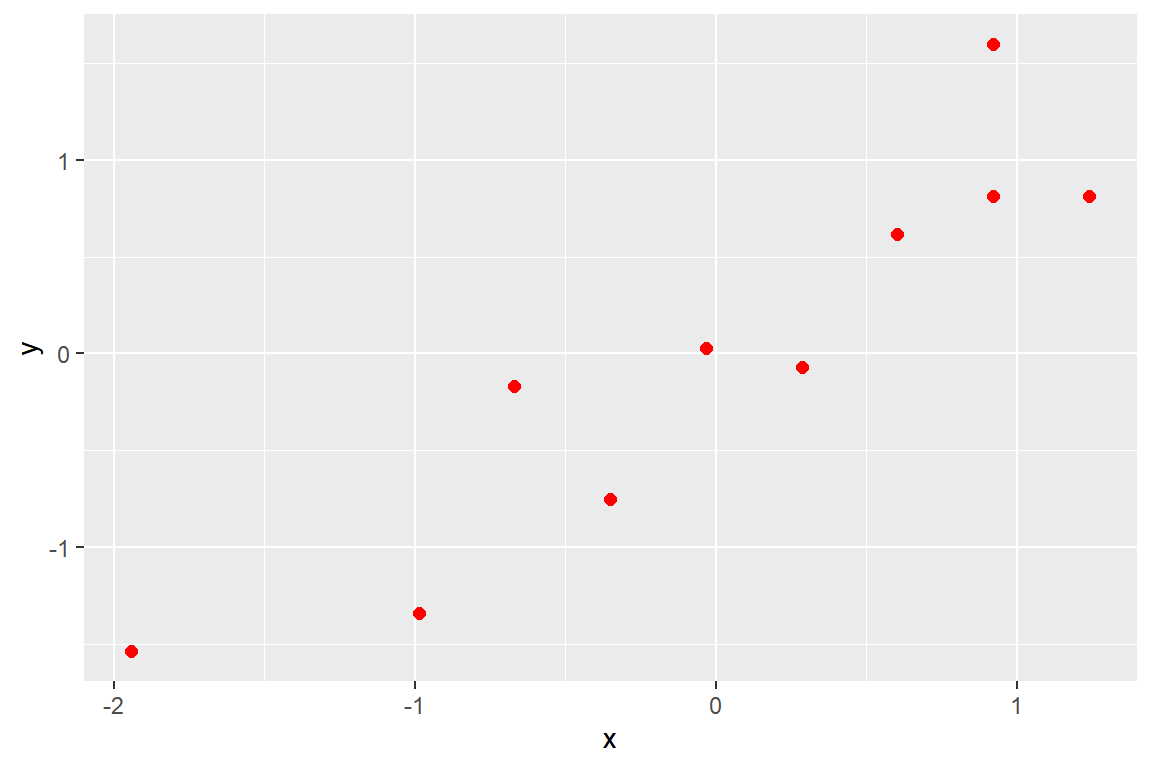
그림 7.1: 생략부호를 활용한 그래프
만일 함수 my_plot()에 NA가 있는 데이터를 입력한다면 어떻게 되겠는가?
표준화 과정에서 데이터는 모두 NA로 바뀌게 되어 결국 그래프 작성이 불가능하게 될 것이다.
데이터 프레임 airquality의 변수 Solar.R과 Ozone을 함수 my_plot()에 입력해 보면 확인할 수 있다.
이 경우, 옵션 na.rm = TRUE를 사용하기 위해 함수 mean()과 sd()에 다음과 같이 생략부호 변수를 포함시킨다고 해서 문제가 해결되지 않는다.
my_plot_1 <- function(x, y, ...){
z_x <- (x - mean(x, ...))/sd(x, ...)
z_y <- (y - mean(y, ...))/sd(y, ...)
ggplot(tibble(x = z_x, y = z_y)) +
geom_point(aes(x, y), ...)
}그 이유는 함수 my_plot_1()에 추가된 옵션이 함수 mean()과 sd(), 그리고 geom_point()에 모두 전달이 되기 때문이다.
즉, 옵션 shape 혹은 color 등을 추가하면 그것이 함수 mean()과 sd()에도 입력되는데,
두 함수에는 그런 옵션이 없기 때문에 다음과 같은 오류가 발생한다.
with(airquality, my_plot_1(x = Solar.R, y = Ozone,
na.rm = TRUE,
shape = 20, color = "red", size = 3))
## Error in sd(x, ...): unused arguments (shape = 20, color = "red", size = 3)따라서 결측값에 대한 옵션을 다음과 같이 변수로 지정하는 것이 문제를 해결하는 한 가지 방법이 된다.
my_plot_2 <- function(x, y, na = FALSE, ...){
z_x <- (x - mean(x, na.rm = na))/sd(x, na.rm = na)
z_y <- (y - mean(y, na.rm = na))/sd(y, na.rm = na)
ggplot(tibble(x = z_x, y = z_y)) +
geom_point(aes(x, y), ...)
}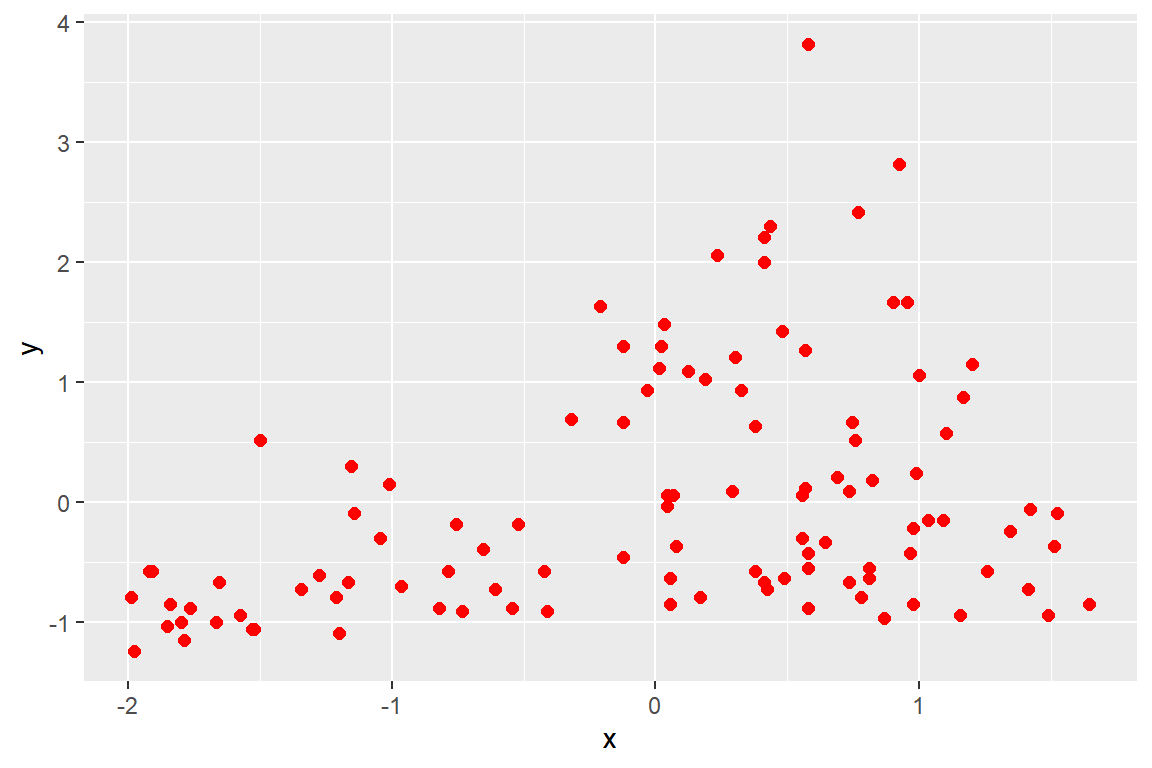
그림 7.2: 생략부호를 활용한 그래프
7.1.3 변수 지정
두 개의 변수를 가지고 있는 다음과 같은 함수 my_power()를 살펴보자.
함수를 실행하기 위해서는 함수에 포함된 변수에 값을 지정해야 한다.
함수 my_power()을 사용하여 \(2^{5}\)을 계산한다면 두 변수인 base와 exponent에 값을 지정해 주어야 하
는데, 함수의 변수를 지정하는 방법에는 다음 세 가지가 있다.
- 전체 이름: 함수를 정의할 때 사용된 변수의 이름 전체를 사용하여 지정하는 방법
- 부분 이름: 함수를 정의할 때 사용된 변수 이름의 처음 일부분만을 사용하여 지정하는 방법
- 변수의 순서: 함수를 정의할 때 지정된 변수의 순서
변수의 전체 이름 혹은 부분 이름을 사용하는 경우에는 변수의 입력순서가 문제가 되지 않는다. 부분 이름을 사용할 경우에는 다른 변수와 구분이 될 만큼은 입력해야 한다. 당장의 편리함만을 생각한다면 순서로 변수를 지정하는 방법을 사용하는 것이 좋을 듯하나, 어떤 값이 어떤 변수에 대한 것인지 불분명하게 될 가능성이 있기 때문에, 조금은 귀찮지만 전체 이름을 모두 사용하여 지정하는 것이 가장 안전하고 명확하게 프로그램을 작성하는 방법이라고 하겠다.
7.1.4 결과의 출력
함수의 연산 결과는 함수 return()으로 출력하는 것이 바람직하다.
예를 들어 다음의 함수 my_desc()는 입력된 벡터의 평균과 표준편차를 계산하여 리스트 형태로 출력하는 내용의 함수이다.
my_desc <- function(x, ...){
m.x <- mean(x, ...)
sd.x <- sd(x, ...)
res <- list(mean = m.x, sd = sd.x)
return(res)
}연산 결과는 리스트 객체 res에 할당되었고 그 결과는 함수 return()으로 출력되는 절차를 밟고 있다.
함수 my_desc()에 데이터 프레임 cars의 dist와 airquality의 Ozone을 각각 적용시키고, 그 결과를 살펴보자.
with(airquality, my_desc(x = Ozone, na.rm = TRUE))
## $mean
## [1] 42.12931
##
## $sd
## [1] 32.98788함수 return()을 사용하지 않으면 가장 마지막에 실행된 표현식의 결과가 출력된다.
따라서 만일 마지막 표현식이 실행결과를 객체에 할당하는 것이라면 아무런 결과도 출력
되지 않는다.
함수 my_desc()에서 함수 return()을 생략하고자 한다면 다음과 같이 수정해야 한다.
결과를 출력할 때 함수 return()을 사용할지 여부는 사용자의 취향에 달린 문제이기는 하지만 함수 return()을 사용하는 편이 훨씬 명확하게 프로그램을 작성하는 방법이 된다.
7.1.5 유효 범위
함수에서 정의되고 사용되는 변수와 생성되는 객체들은 모두 해당 함수 안에서만 존재한다.
즉, 만일 어떤 함수 내에서 x라는 변수를 정의하고 사용하였어도, 함수 밖에서는 그 변수를 사용할 수 없다는 것이다.
예를 들어, 벡터 x와 y가 현재의 작업 공간에 없다고 하자.
그러면, 함수 my_test()에서는 변수 x가 사용되고 객체 y가 생성되어 출력되었으나, 함수 밖에서는 모두 사용할 수 없는 대상인 것이다.
만일 같은 이름의 객체가 함수 안과 밖에 모두 존재하더라도 이들은 서로 전혀 상관없는 객체이다.
즉, 함수의 안과 밖은 서로 분리된 환경(environment)으로서 함수는 변수에 지정할 값을 함수 외부로부터 받아들여 함수 내부에서 연산하고 그 결과를 다시 함수 외부로 내보내는 방식으로 외부와 소통하고 있다. 이와 같이 프로그램 내에서 특정 변수가 정의되어 사용될 수 있는 부분을 유효 범위(scope)라고 한다. 함수 내에서 사용되는 변수의 유효 범위를 제한하는 것은 반드시 필요한 사항인데, 이것은 어떤 함수에서 정의된 객체의 내용이 다른 함수에서 같은 이름의 객체를 사용했다고 해서 변경되는 것을 방지하기 위함이다.
여기서 유의할 점은 함수 내부의 변수들은 유효 범위가 제한되어 있지만 함수 외부의 변수들은 그렇지 않다는 점이다. 만일 함수 외부에서 정의된 변수가 있는데, 함수 내부에 그와 동일한 이름의 변수가 따로 지정된 것이 없다면, 함수 내부에서도 그대로 사용할 수 있게 된다. 이러한 일종의 비대칭적인 유효 범위의 설정 덕분에 상당히 효과적인 프로그래밍이 가능하게 되었다. 다음의 예를 살펴보자.
함수 외부의 상황에 따라 계산 결과를 다르게 할 수 있음을 보여주는 예가 된다.
7.1.6 데이터 프레임 함수
지금까지 살펴본 함수는 입력 요소가 모두 벡터였다.
프로그램 과정에서 충분히 나름의 역할을 할 수 있는 방식인 것은 분명하지만, 파이프 연산 과정에 포함시켜 사용하기에는 다소 불편한 점이 있다고 하겠다.
그것은 7장에서 살펴본 바와 같이 dplyr 기본 함수들의 공통적인 특징은 첫 번째 입력 변수가 데이터 프레임이기 때문이다.
지금부터는 데이터 프레임을 첫 번째 입력 요소로 하는 데이터 프레임 함수을 정의하는 방식에 대해 살펴보겠다. 먼저 예제를 통해 벡터 함수를 정의하고, 그것을 단순하게 데이터 프레임 함수로 전환했을 때 발생할 수 있는 문제와 해결 방법을 살펴보자.
\(\bullet\) 예제: 벡터 함수 my_mean() 정의
입력변수로 숫자형 변수 하나와 범주형 변수 하나를 받아서, 범주형 변수로 그룹을 구성하고 각 그룹별로 숫자형 변수의 평균값을 계산해서 출력하는 함수를 정의해 보자.
함수 my_mean()에 mpg의 변수 hwy와 drv를 입력한 결과는 다음과 같다.
with(mpg, my_mean(hwy, drv))
## # A tibble: 3 × 2
## y m
## <chr> <dbl>
## 1 4 19.2
## 2 f 28.2
## 3 r 21airquality의 변수 Ozone과 Month을 입력한 결과는 다음과 같다.
with(airquality, my_mean(Ozone, Month, na.rm = TRUE))
## # A tibble: 5 × 2
## y m
## <int> <dbl>
## 1 5 23.6
## 2 6 29.4
## 3 7 59.1
## 4 8 60.0
## 5 9 31.4\(\bullet\) 예제: 데이터 프레임 함수 my_mean_df() 정의의
데이터 프레임을 my_mean()의 첫 번째 변수로 추가해 보자.
함수 my_mean_df()는 my_mean()에 데이터 프레임을 첫 번째 변수로 단순히 추가해서 수정한 함수이다.
my_mean_df()에 mpg, hwy, drv를 입력해서 실행하면 다음과 같은 오류가 발생한다.
mpg |>
my_mean_df(hwy, drv)
## Error in `group_by()`:
## ! Must group by variables found in `.data`.
## ✖ Column `y` is not found.오류의 내용은 변수 y가 입력된 데이터 프레임에 없다는 것이다.
이것은 my_mean_df()의 변수 x에 hwy를, y에 drv를 각각 지정했지만, 함수의 실행 과정에서는 여전히 변수 x와 y를 찾고 있다는 것을 의미한다.
따라서 실행 과정에서 이름이 x와 y인 변수를 찾는 것이 아니라, 입력 변수 x와 y에 지정되는 변수를 사용하도록 조치할 필요가 있는 것이다.
이 문제는 {{}}를 함수 실행 과정에서 사용되는 입력 변수에 감싸는 것으로 해결된다.
{{x}}와 {{y}}는 이름이 x와 y인 변수가 아니라, 함수 my_mean_df()의 입력 변수인 x와 y에 지정된 변수를 의미한다.
my_mean_df <- function(data, x, y, ...){
data |>
group_by({{y}}) |>
summarise(m = mean({{x}}, ...))
}수정된 my_mean_df()에 mpg, hwy, drv를 입력해서 실행해 보자.
mpg |>
my_mean_df(hwy, drv)
## # A tibble: 3 × 2
## drv m
## <chr> <dbl>
## 1 4 19.2
## 2 f 28.2
## 3 r 21airquality와 Ozone과 Month을 입력한 결과는 다음과 같다.
7.2 조건 연산
주어진 조건의 만족 여부에 따라 실행되는 표현식을 다르게 할 수 있는데, 이러한 작업은 함수 if(), ifelse() 혹은 switch()로 할 수 있다.
7.2.1 함수 if()에 의한 조건 연산
함수 if()의 일반적인 사용법은 다음과 같다.
if(조건){
표현식
}조건이 만족되는 경우에만 표현식이 실행되는 구조이다.
함수 if()는 else 부분을 포함시킬 수도 있는데, 그 형태는 다음과 같다.
if(조건) {
표현식 1
} else {
표현식 2
}이 경우 조건이 만족되면 표현식 1이 실행되고 만족되지 않으면 표현식 2가 실행된다. 위 구조는 다음과 같이 더 확장될 수 있다.
if(조건 1) {
표현식 1
} else if(조건 2) {
표현식 2
} else {
표현식 3
}조건 1이 만족되면 표현식 1이 실행되고, 조건 2가 만족되면 표현식 2가 실행되며, 두 조건 모두 만족되지 않으면 표현식 3이 실행되는 구조이다.
예제로 근의 공식을 이용하여 이차방정식의 근을 구하는 프로그램을 작성해 보자. 이차방정식 \(ax^{2}+bx+c=0\) 의 근의 개수는 판별식 \(D=b^{2}-4ac\) 의 값에 따라 3가지로 분류된다. 따라서 판별식의 실행 값이 조건이 되어 3가지 경우에 대한 표현식을 작성해야 한다.
find_roots <- function(a,b,c){
if(a == 0){
roots <- c("Not quadratic equation")
} else{
D <- b^2 - 4*a*c
if(D > 0){
roots <- c((-b - sqrt(D))/(2*a),(-b + sqrt(D))/(2*a))
} else if(D == 0){
roots <- -b/(2*a)
} else{
roots <- c("No real root")
}
}
return(roots)
}사용자 정의 함수 find_roots()를 이용하여 이차방정식 \(x^{2}+4x+3=0\) 의 근을 다음과 같이 구할 수 있다.
함수 if()를 사용할 때 조심해야 할 사항이 두 가지 있다.
첫 번째 사항은 else에 대한 것인데, 만일 다음과 같이 프로그램을 작성하면 오류가 발생한다.
if(조건) {
표현식 1}
else {
표현식 2
}문제는 새로운 줄이 else로 시작했다는 것인데, 이렇게 작성이 되면 함수 if()는 ’표현식 1’에서 종료된 것으로 간주된다. 이어서 R은 else라는 함수를 찾게 되는데, 그런 함수가 없기 때문에 오류가 발생하는 것이다.
두 번째 사항으로 if()의 조건에는 하나의 논리값만이 사용되어야 한다는 점이다.
만일 길이가 1을 초과라는 논리 벡터가 입력되면 오류가 발생한다.
길이가 4인 두 벡터를 비교하여 큰 값을 차례로 출력하고자 하는 경우 함수 if()로 작성하면 다음과 오류가 발생한다.
7.2.2 함수 ifelse()에 의한 조건 연산
조건 연산이 하나의 논리값에 의한 것이 아니라 논리 벡터에 의한 것이라면 함수 ifelse() 또는 dplyr::if_else()를 사용해야 한다.
함수 ifelse() 사용법은 ifelse(condtion, true, false)가 되는데,
condition은 조건 연산으로 생성되는 논리형 벡터이고,
논리형 벡터의 값이 TRUE인 경우에는 true의 값이 할당되고, FALSE인 경우에는 false의 값이 할당된다.
함수 dplyr::if_else()의 사용법도 동일하다.
두 벡터를 비교하여 큰 값을 차례로 출력하고자 했던 앞의 예제는 다음과 같이 해결할 수 있다.
주어진 점수가 50 미만이면 ‘Fail’, 50 이상이면 ‘Pass’를 점수와 함께 출력시키는 프로그램을 작성해 보자.
7.2.3 함수 switch()에 의한 조건 연산
함수 switch()는 표현식이 갖는 값에 따라 몇 가지 항목 중 하나를 선택하는 기능을 갖고 있는 함수이다.
사용법은 switch(표현식, 선택 항목)인데, 표현식이 갖는 값이 숫자인 경우와 문자인 경우에 따라 선택하는 방식에 차이가 있다.
표현식의 결과가 숫자인 경우에는 선택할 항목의 위치를 지정하는 것이다.
예를 들어 Park, Lee, Kim 중 한 사람을 임의로 선택해야 한다면,
함수 sample()로 1, 2, 3 중 숫자 하나를 임의로 뽑고,
그 숫자를 세 사람의 이름이 콤마로 구분되어 있는 선택 항목과 함께 함수 switch()에 입력한다.
그러면 입력된 숫자의 위치에 있는 사람을 선택하게 된다.
표현식의 결과가 문자인 경우에는 선택할 항목 중 그 문자와 같은 항목을 선택하게 된다.
예를 들어 자료의 특성을 보고, 그 자료의 대푯값으로 산술평균과 중앙값 중 하나를 선택해서 계산할 수 있도록 하는 함수를 작성해 보자.
함수 my_center()는 입력되는 변수 type의 값에 따라 함수 mean() 혹은 median()을 사용하게 된다.
벡터 x에 1, 2, 3, 4, 50이 입력되어 있을 경우, 산술평균과 중앙값 중 하나를 선택해서 대푯값을 계산해 보자.
\(\bullet\) 예제 : 함수 정의
입력 변수의 유형은 벡터이며, 숫자형 변수를 입력하면 평균과 표준편차를, 요인을 입력하면 도수분포를 출력하고, 그 외 형태를 입력하면, “Input Error”이라는 문구를 출력하는 함수 my_desc()를 정의해 보자.
if()의 구조를 이용해서 입력되는 변수의 유형에 따른 작업을 지정하면 된다.
my_desc <- function(x, ...){
if(is.numeric(x)){
res <- data.frame(Mean = mean(x, ...), SD = sd(x, ...))
} else if(is.factor(x)){
res <- data.frame(x) |> count(value = x)
} else res <- c("Input Error")
return(res)
}패키지 MASS에 있는 Cars93의 변수 MPG.highway와 Origin을 각각 입력한 결과는 다음과 같다.
\(\bullet\) 예제 : 함수 my_desc() 수정
데이터 프레임을 함수 my_desc()의 첫 번째 변수로 입력할 수 있도록 수정해 보자.
my_desc_df <- function(data, var, ...){
x <- data |>
pull({{var}})
if(is.numeric(x)){
res <- data.frame(Mean = mean(x, ...), SD = sd(x, ...))
} else if(is.factor(x)){
res <- data.frame(x) |> count(value = x)
} else res <- c("Input Error")
return(res)
}my_desc_df()의 두 번째 변수 var는 데이터 프레임의 변수 중 하나가 되는데, 이것을 {{}}로 감싸고 x에 할당함으로써, 이후 계산 과정에서는 변수 x가 있는 위치로 연결되는 것이다.
7.3 루프 연산
프로그램의 특정 부분을 일정 횟수 반복시켜 작업하는 것을 루프 연산이라고 한다.
R에서 루프 연산은 함수 for()와 while()로 할 수 있다.
7.3.1 for 루프
정규분포에서 10개의 임의표본을 추출하여 평균을 계산하는 과정을 다섯 번 반복한다고 하자. 이 경우 동일한 명령문을 다음과 같이 다섯 번 작성해서 차례로 실행하는 것은 그리 좋은 방법은 아니다.
set.seed(123)
r1 <- rnorm(10) |> mean()
r2 <- rnorm(10) |> mean()
r3 <- rnorm(10) |> mean()
r4 <- rnorm(10) |> mean()
r5 <- rnorm(10) |> mean()거의 비슷한 연산을 반복해서 수행해야 한다면 for 루프를 사용하는 것이 바람직하다.
다음 예제로 함수 for()의 사용법을 살펴보자.
for 루프는 세 가지 요소로 구성되어 있다.
첫 번째는 루프 연산으로 생성될 결과물 객체를 위한 빈 공간의 생성이다.
즉, 비어있는 벡터를 미리 만드는 것인데, 루프 연산으로 산출된 결과값의 할당이 대부분 대괄호를 이용한 인덱싱으로 이루어지기 때문에, 미리 이것을 대비한 것이다.
빈 공간의 생성은 함수 vector()로 할 수 있는데, 함수 안에 벡터의 유형과 벡터의 길이를 지정해야 한다.
벡터의 유형은 "logical", "integer", "double", "character" 등이 가능하다.
두 번째 요소는 반복 횟수 및 반복 인덱스 변수의 지정이다.
일반적으로 for(var in seq)의 형태를 취하는데, 인덱스 변수 var는 seq의 값을 차례로 취하면서 루프를 수행하게 된다.
위의 예제에서는 인덱스 변수로 i가 사용되었고, 루프가 수행되면서 i가 seq_along(res)의 값인 1, 2, 3, 4, 5의 값을 차례로 취하게 된다.
세 번째 요소는 중괄호 안에서 반복 수행이 되는 표현식이다.
그 중 가장 중요한 부분은 수행 결과물을 미리 공간을 확보한 결과물 벡터에 대괄호를 이용한 인덱싱 기법으로 할당하는 것이다.
즉, 첫 번째 반복에서는 res[1] <- mean(rnorm(10))으로 결과물을 할당하고,
두 번째 반복에서는 res[2] <- mean(rnorm(10))이 수행되는 식이 된다.
for 루프를 활용한 다른 예제로서 factorial 값을 계산해 보자.
fac.x <- 1
for(i in 1:5){
fac.x <- fac.x*i
cat(i, "!=", fac.x, "\n", sep="")
}
## 1!=1
## 2!=2
## 3!=6
## 4!=24
## 5!=120Factorial의 계산절차는 먼저 변수 fac.x에 초기값 1을 할당하고 이어서 for 루프로 들어가 본격적인 연산을 한다.
루프 안에서는 먼저 변수 i가 1의 값을 갖고 fac.x <- fac.x*i를 실행한 후 함수 cat()으로 ‘1!=1’을 출력함으로써 첫 번째 연산이 종료된다.
두 번째 연산에서는 변수 i가 2가 되고 할당 기호 오른쪽의 fac.x는 이전 연산에서 할당된 1의 값을 갖고 있어서 1×2의 값이 다시 fac.x에 할당된다.
세 번째 연산에서는 변수 i가 3, 할당 기호 오른쪽의 fac.x는 1×2가 됨으로 1×2×3이 fac.x의 새로운 값이 된다.
네 번째와 다섯 번째도 동일한 작업이 반복되어 factorial 계산을 마치게 된다.
함수 cat()은 여러 개의 데이터 객체를 한데 묶어서 출력할 때 유용하게 사용되는 함수이다.
문자열 "\n"을 입력하여 다음 연산의 결과가 새로운 줄에서 출력되도록 하였다.
7.3.2 while 루프
for 루프를 사용하기 위해서는 반복 횟수가 명확하게 정해져야 한다.
그러나 어떤 경우에는 특정 조건이 만족될 때까지 반복을 지속해야 할 때도 있다.
이런 상황에서는 for 루프를 사용할 수 없고, 대신 while 루프를 사용해야 한다.
함수 while()에 의한 루프 연산의 일반적인 사용법은 다음과 같다.
중괄호 안의 표현식은 조건이 만족되는 동안 계속해서 실행된다.
while(조건){
표현식
}for 루프 연산은 while 연산으로 전환이 가능하다.
Factorial 계산 예제를 while 루프 연산으로 계산해 보자.
루프 연산 이전에 인덱스 변수 i에 초기값 1을 할당하고, 루프 연산마다 인덱스 변수에 1을 더해 주는 작업을 추가하면 전환이 가능하다.
fac.x <- 1
i <- 1
while(i <= 5){
fac.x <- fac.x*i
cat(i, "!=", fac.x, "\n", sep="")
i <- i+1
}
## 1!=1
## 2!=2
## 3!=6
## 4!=24
## 5!=120for 루프보다 while 루프를 사용하는 것이 더 적절한 다음 예제를 살펴보자.
\(N(1, 2^{2})\) 에서 \(n=5\) 의 표본을 추출해서 표본평균을 계산하는 과정을 최대 20번 반복을 한다. 만일 표본평균값이 음수가 되면 해당 반복횟수를 출력하고 루프를 종료하며, 20회를 반복해서 계산한 표본평균값이 모두 양수이면 “All positive mean values”라는 문구를 출력한다.
이 문제에서 루프의 진행 조건은 표본평균값이 양수인 것과 반복횟수가 최대 반복횟수인 20회를 넘지 않는 것이 된다.
따라서 두 조건을 while()에 다음과 같이 명시를 하면 된다.
n_iter <- 1
max_iter <- 20
mean_val <- 1
while(mean_val >= 0 & n_iter <= max_iter){
mean_val <- mean(rnorm(5, mean = 1, sd = 2))
if(mean_val < 0) cat("Negative mean value at", n_iter, "iteration")
n_iter <- n_iter + 1
if(n_iter == max_iter) cat("All positive mean values")
}
## Negative mean value at 3 iteration7.4 함수형 프로그래밍
동일한 작업이 반복되어야 하는 상황에서 루프 연산은 좋은 대안이라 할 수 있다. 하지만 루프 연산도 항상 좋은 평가를 받고 있는 것은 아니다. 프로그램의 의미 파악이 쉽지 않다는 문제가 자주 지적되곤 한다. 루프 연산에 대한 대안으로 제시되는 것이 함수형(functional) 프로그래밍이다.
Functional이란 함수를 입력 변수로 받는 함수를 의미한다.
예를 들어 다음과 같이 정의된 함수 my_desc()는 벡터와 요약통계 함수를 입력 변수로 받아 자료의 요약통계량을 출력하는 단순한 형태의 functional이 된다.
함수를 입력변수로 받을 수 있는 함수 중 중요하게 사용되는 함수가 lapply()와 sapply()이다.
함수 lapply()의 기본적인 사용법은 lapply(X, FUN, ...)이며, 여기서 X는 벡터 또는 리스트가 된다.
입력된 벡터 또는 리스트의 각 요소마다 FUN에 지정한 함수를 적용하여 그 결과를 리스트로 출력하는 것이 lapply()의 기본적인 작동 방식이다.
함수 sapply()는 사용법이 lapply()와 동일하지만 결과를 내보내는 방식이 sapply()는 벡터 혹은 행렬이 된다는 점에서 lapply()와 차이가 있다.
함수 lapply() 또는 sapply()는 for 루프 연산을 함수형 프로그래밍으로 전환할 때 매우 유용하게 사용되는 함수이다.
예를 들어 데이터 프레임 iris에 있는 모든 변수의 class 속성을 확인해 보자.
우선 for 루프 연산을 이용해 보자.
res <- vector("character", length(iris))
names(res) <- names(iris)
for(i in seq_along(res)){
res[i] <- class(iris[[i]])
}
res
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## "numeric" "numeric" "numeric" "numeric" "factor"동일한 내용의 작업을 함수 sapply()을 이용하여 실행해 보자.
훨씬 단순하고 쉽게 작업할 수 있음을 알 수 있다.
sapply(iris, class)
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## "numeric" "numeric" "numeric" "numeric" "factor"루프 연산과 함수형 프로그래밍의 비교를 위한 또 다른 예제로 평균이 각각 -2, -1, 0, 1, 2이고 표준편차가 0.5인 정규분포에서 10개씩의 임의표본을 추출하여 평균값을 계산해보자. 먼저 루프 연산으로 실행해 보자.
set.seed(1234)
m <- -2:2
res <- vector("double", length(m))
for(i in seq_along(res)){
res[i] <- mean(rnorm(n = 10, mean = m[i], sd = 0.5))
}
res
## [1] -2.1915787 -1.0590854 -0.1939734 0.6169035 1.6951015동일한 내용의 작업을 함수 lapply()와 sapply()를 이용해서 실행해 보자.
루프 연산에서는 실제로 두 가지 작업이 한꺼번에 수행되었는데, 하나는 정규분포에서 난수를 발생
하는 것이고, 다른 하나는 자료의 평균값을 계산하는 것이다.
함수형 프로그래밍에서는 두가지 작업을 분리하여 실행해야 할 것으로 보인다.
우선 다섯 개의 정규분포에서 10개의 난수를 각각 발생시켜, 그 결과를 리스트에 보관하는 작업을 lapply()로 실행해 보자.
이어서 리스트 각 요소에 mean()을 적용하는 것인데, 이 작업은 결과를 벡터로 출력하기 위해서 sapply()로 실행해 보자.
set.seed(1234)
m <- -2:2
x <- lapply(m, rnorm, n = 10, sd = 0.5)
sapply(x, mean)
## [1] -2.1915787 -1.0590854 -0.1939734 0.6169035 1.6951015만일 앞 예제에서 10개 자료에 대한 평균값뿐만이 아니라 표준편차 등 다른 요약통계량 값도 계산해야 한다고 하자.
함수 sapply()의 경우에는 mean 대신 sd를 입력하여 sapply(x, sd)를 한 번 더 실행하거나 또는 다른 필요한 함수를 대신 입력하면 되는 간단한 문제이지만,
루프 연산의 경우에는 프로그램에서 필요한 함수만 바꾸고 전체를 다시 입력하고 실행해야 되는 번거로운 일이 된다.
따라서 루프 연산을 사용하는 경우에라도 함수형 프로그래밍의 장점을 활용할 수 있도록 다음과 같이 사용자 정의 함수 안에 루프 연산을 집어넣는 것이 훨씬 효과적이다.
my_desc <- function(x, fun){
res <- vector("double", length(x))
for(i in seq_along(res)){
res[i] <- fun(x[[i]])
}
return(res)
}함수 my_desc()는 루프 연산을 사용하고 있으나, 함수를 입력 변수로 지정할 수 있도록 조정하였다.
사실상 함수 sapply()와 동일한 함수라고 할 수 있다.
7.5 함수형 프로그래밍으로 행렬과 데이터 프레임 다루기
행렬과 데이터 프레임을 대상으로 데이터 분석할 때 반복된 작업이 필요한 경우가 있다. 예를 들어 주어진 행렬의 각 열 또는 각 행의 평균값을 계산해야 한다고 하자. 이런 경우에 for 루프에 의한 반복 작업보다는 함수형 프로그래밍을 적절하게 적용하면 매우 효과적으로 작업을 진행할 수 있다.
7.5.1 행렬에 함수형 프로그래밍 적용하기
행렬에 적용할 수 있는 functional은 함수 apply()이다.
기본적인 사용법은 apply(X, MARGIN, FUN, ...)인데, 여기서 X는 행렬 또는 배열이고, MARGIN은 FUN에 지정한 함수가 적용되는 방향을 나타내는 정수로써, MARGIN = 1이면 행 방향, MARGIN = 2이면 열 방향으로
함수를 적용한다.
예를 들어 A라는 행렬에 Park, Lee, Kim의 세 사람에 대한 반복된 측정값이 들어 있다고 하자.
A
## trial1 trial2 trial3 trial4
## Park 0.8 1.1 0.0 0.6
## Lee 1.3 1.3 1.2 1.4
## Kim 1.0 1.3 0.2 0.6세 사람마다 반복 측정된 값들의 평균값을 apply()를 사용하여 계산해 보자.
이것은 행렬 A의 각 행에 mean()을 적용하는 것이므로 MARGIN = 1이 된다.
함수의 적용 결과가 벡터로 나오게 되면 apply()의 결과는 행렬이 된다.
이번에는 행렬 A 각 열의 평균값을 계산해 보자.
7.5.2 데이터 프레임에 함수형 프로그래밍 적용하기
\(\bullet\) 그룹별 요약통계량 계산
데이터 프레임의 변수 중에 요인이 있다면 그 요인의 수준(level)에 따라 다른 변수의 관찰값들을 따로 묶을 수 있다. 이런 경우 요인의 수준에 의해 구분되는 그룹에 따라 특정 변수의 분포에 어떤 차이가 있는지를 알아보는 것은 중요한 분석 과제가 될 수 있다.
이런 경우 사용할 수 있는 functional에는 함수 tapply()가 있다.
기본적인 사용법은 tapply(X, INDEX, FUN, simplify = TRUE)이다.
여기서 X는 벡터이고, INDEX는 요인, FUN은 요약통계량을 계산하는 함수이며,
simplify는 출력 형태를 지정하는 것으로 디폴트(TRUE) 값이 주어지면 벡터, FALSE가 주어지면 리스트로 출력된다.
동일한 내용의 작업을 함수 split()과 lapply()를 연이어 사용해도 수행할 수 있다.
함수 split()은 벡터 혹은 데이터 프레임을 요인에 따라 그룹을 분리하여 리스트로 출력하는 기능을 갖고 있다.
사용법은 split(x, f)이며, x는 벡터 또는 데이터 프레임이고, f는 요인이다.
패키지 MASS에 있는 Cars93에는 요인으로 Origin이라는 변수가 있는데, USA와 non-USA의 2개 수준이 있다.
변수 MPG.city를 Origin에 따라 두 그룹으로 구분하여 평균값을 비교해 보자.
먼저 함수 tapply()로 그룹별 평균을 구해 보자.
with(Cars93, tapply(MPG.city, Origin, mean, simplify = FALSE))
## $USA
## [1] 20.95833
##
## $`non-USA`
## [1] 23.86667이번에는 함수 split()으로 그룹별 자료를 분리하여 리스트에 저장하고, 이어서 함수 lapply() 또는 sapply()를 적용해 보자.
x_g <- with(Cars93, split(MPG.city, Origin))
str(x_g)
## List of 2
## $ USA : int [1:48] 22 19 16 19 16 16 25 25 19 21 ...
## $ non-USA: int [1:45] 25 18 20 19 22 46 30 24 42 24 ...그룹별 요약통계량을 구하는 작업은 패키지 dplyr의 함수 group_by()와 summarise()를 사용해도 구할 수 있다.
Cars93 |>
group_by(Origin) |>
summarise(m = mean(MPG.city), n = n())
## # A tibble: 2 × 3
## Origin m n
## <fct> <dbl> <int>
## 1 USA 21.0 48
## 2 non-USA 23.9 45\(\bullet\) 데이터 프레임의 모든 변수에 함수 적용
행렬의 경우 모든 열에 특정 함수를 각각 적용시킬 때 사용할 수 있는 함수는 apply()이다.
즉, apply(X, 2, FUN)를 실행시키면 주어진 행렬 X의 모든 열에 특정 함수 FUN을 적용시킬 수 있다.
데이터 프레임도 행렬과 같이 2차원 배열이기 때문에 함수 apply()를 적용할 수는 있다.
그러나 함수 apply()를 데이터 프레임에 적용하여 원하는 결과를 얻기 위해서는 주어진 데이터 프레임의 모든 데이터들이 동일한 유형이어야 한다는 문제가 있다.
즉, 모두 숫자이거나 문자이어야 한다.
데이터 프레임의 모든 데이터들이 동일한 유형일 가능성은 높지 않기 때문에 함수 apply()를 사용하기에는 적절하지 않은 상황이 많을 것이다.
이런 경우 함수 lapply()와 sapply()를 대신 사용할 수 있다.
두 함수는 벡터나 리스트의 각 요소에 동일한 함수를 적용하는 기능을 가진 함수이다.
데이터 프레임은 행렬과 같은 2차원 구조이지만 함수 typeof()로 확인할 수 있는 유형은 리스트이다.
따라서 함수 lapply()나 sapply()를 사용할 수 있는데, 이 경우에는 데이터 프레임의 각 변수(열)에 동일한 함수가 적용된다.
패키지 MASS에 있는 데이터 프레임 cabbages에는 4개의 변수가 있는데,
이 변수들의 class 속성을 벡터로 출력하고자 한다면 어떻게 해야 하겠는가?
함수 sapply()를 이용하여 데이터 프레임 cabbages의 네 변수에 함수 class()를 적용시켜 보자.
data(cabbages, package = "MASS")
sapply(cabbages, class)
## Cult Date HeadWt VitC
## "factor" "factor" "numeric" "integer"함수 apply()로 데이터 프레임 cabbages에 있는 4개 변수의 class 속성을 확인해 보자.
함수 sapply()에 의한 결과와는 다르게 모든 변수가 문자형으로 나타났다.
어떤 문제가 발생한 것일까?
apply(cabbages, 2, class)
## Cult Date HeadWt VitC
## "character" "character" "character" "character"데이터 프레임 airquality를 구성하는 모든 변수의 평균값을 구해 보자.
측정 일자를 나타내는 변수 Month와 Day를 제외한 네 변수의 평균값을 함수 sapply()로 계산해 보자.
airs |>
sapply(mean, na.rm = TRUE)
## Ozone Solar.R Wind Temp
## 42.129310 185.931507 9.957516 77.882353함수 sapply() 대신 패키지 dplyr의 함수 across()를 summarise()와 함께 사용해도 같은 결과를 얻을 수 있다.
airs |>
summarise(across(everything(), ~ mean(.x, na.rm = TRUE)))
## Ozone Solar.R Wind Temp
## 1 42.12931 185.9315 9.957516 77.88235데이터 프레임 airquality의 분석 목적은 변수 Ozone의 변동을 Solar.R과 Wind, 그리고 Temp로 설명하는 모형을 만드는 것이다.
분석의 첫 단계로 네 변수 사이의 상관계수를 월별로 구분하여 계산해 보자.
먼저 함수 split()으로 데이터 프레임 airquality를 월별로 구분하여 리스트로 저장하자.
리스트 airs_list의 각 요소는 월별로 구분된 데이터 프레임이다.
str(airs_list)
## List of 5
## $ 5:'data.frame': 31 obs. of 4 variables:
## ..$ Ozone : int [1:31] 41 36 12 18 NA 28 23 19 8 NA ...
## ..$ Solar.R: int [1:31] 190 118 149 313 NA NA 299 99 19 194 ...
## ..$ Wind : num [1:31] 7.4 8 12.6 11.5 14.3 14.9 8.6 13.8 20.1 8.6 ...
## ..$ Temp : int [1:31] 67 72 74 62 56 66 65 59 61 69 ...
## $ 6:'data.frame': 30 obs. of 4 variables:
## ..$ Ozone : int [1:30] NA NA NA NA NA NA 29 NA 71 39 ...
## ..$ Solar.R: int [1:30] 286 287 242 186 220 264 127 273 291 323 ...
## ..$ Wind : num [1:30] 8.6 9.7 16.1 9.2 8.6 14.3 9.7 6.9 13.8 11.5 ...
## ..$ Temp : int [1:30] 78 74 67 84 85 79 82 87 90 87 ...
## $ 7:'data.frame': 31 obs. of 4 variables:
## ..$ Ozone : int [1:31] 135 49 32 NA 64 40 77 97 97 85 ...
## ..$ Solar.R: int [1:31] 269 248 236 101 175 314 276 267 272 175 ...
## ..$ Wind : num [1:31] 4.1 9.2 9.2 10.9 4.6 10.9 5.1 6.3 5.7 7.4 ...
## ..$ Temp : int [1:31] 84 85 81 84 83 83 88 92 92 89 ...
## $ 8:'data.frame': 31 obs. of 4 variables:
## ..$ Ozone : int [1:31] 39 9 16 78 35 66 122 89 110 NA ...
## ..$ Solar.R: int [1:31] 83 24 77 NA NA NA 255 229 207 222 ...
## ..$ Wind : num [1:31] 6.9 13.8 7.4 6.9 7.4 4.6 4 10.3 8 8.6 ...
## ..$ Temp : int [1:31] 81 81 82 86 85 87 89 90 90 92 ...
## $ 9:'data.frame': 30 obs. of 4 variables:
## ..$ Ozone : int [1:30] 96 78 73 91 47 32 20 23 21 24 ...
## ..$ Solar.R: int [1:30] 167 197 183 189 95 92 252 220 230 259 ...
## ..$ Wind : num [1:30] 6.9 5.1 2.8 4.6 7.4 15.5 10.9 10.3 10.9 9.7 ...
## ..$ Temp : int [1:30] 91 92 93 93 87 84 80 78 75 73 ...이제 함수 lapply()를 사용하여 리스트의 각 요소인 월별로 구분된 데이터 프레임에 함수 cor()을 각각 적용시켜 상관계수를 계산하면 된다.
결측값이 있는 데이터이기 때문에 결측값을 제외하고 상관계수를 계산하기 위하여 use = "pairwise"를 추가해야 한다.
airs_list |>
lapply(cor, use = "pairwise")
## $`5`
## Ozone Solar.R Wind Temp
## Ozone 1.0000000 0.2428635 -0.3742975 0.5540792
## Solar.R 0.2428635 1.0000000 -0.2268858 0.4547569
## Wind -0.3742975 -0.2268858 1.0000000 -0.3732760
## Temp 0.5540792 0.4547569 -0.3732760 1.0000000
##
## $`6`
## Ozone Solar.R Wind Temp
## Ozone 1.0000000 0.7177528 0.3572546 0.6683386
## Solar.R 0.7177528 1.0000000 0.3498991 0.4037639
## Wind 0.3572546 0.3498991 1.0000000 -0.1210353
## Temp 0.6683386 0.4037639 -0.1210353 1.0000000
##
## $`7`
## Ozone Solar.R Wind Temp
## Ozone 1.0000000 0.4293259 -0.6673491 0.7227023
## Solar.R 0.4293259 1.0000000 -0.1277751 0.3210154
## Wind -0.6673491 -0.1277751 1.0000000 -0.3052355
## Temp 0.7227023 0.3210154 -0.3052355 1.0000000
##
## $`8`
## Ozone Solar.R Wind Temp
## Ozone 1.0000000 0.5296827 -0.7085496 0.5978993
## Solar.R 0.5296827 1.0000000 -0.1650273 0.3929261
## Wind -0.7085496 -0.1650273 1.0000000 -0.5076146
## Temp 0.5978993 0.3929261 -0.5076146 1.0000000
##
## $`9`
## Ozone Solar.R Wind Temp
## Ozone 1.0000000 0.1803730 -0.6104514 0.8281521
## Solar.R 0.1803730 1.0000000 -0.1013448 0.1230107
## Wind -0.6104514 -0.1013448 1.0000000 -0.5704701
## Temp 0.8281521 0.1230107 -0.5704701 1.0000000만일 월별로 변수 Ozone과 Solar.R의 상관계수만을 계산하여 벡터로 출력하고자 한다면 sapply()에 사용자 정의 함수를 입력하면 된다.
필요한 함수는 다음과 같이 정의할 수 있다.
두 변수의 5월 상관계수는 다음과 같이 계산된다.
함수 sapply()에 cor_air()를 적용하면 다음과 같은 결과를 얻게 된다.
동일한 작업을 anonymous 함수, 즉 이름이 없는 함수를 사용해서 할 수 있다.
함수 sapply()에 입력된 내용은 함수 cor_air()와 실질적으로는 동일하지만, 이름이 없는, 즉 함수 객체로 저장되지 않은 anonymous 함수이다.
7.6 purrr에 의한 프로그래밍
루프 연산의 대안으로써 살펴본 함수 lapply() 등은 base R에 속한 함수이다.
나름의 역할을 충실하게 수행한다고 할 수 있으나, 더 개선된 기능을 갖고 있는 함수들이 core tidyverse에 속한 패키지 purrr에 마련되어 있다.
대표적인 함수는 map()으로서, 기본적인 사용법은 map(.x, .f, ...)이다.
여기서 .x는 벡터 혹은 리스트이고 .f는 .x의 각 요소에 적용하고자 하는 함수이며, 결과는 리스트로 출력된다.
예를 들어 아래에 주어진 리스트 x를 구성하는 세 벡터의 평균을 각각 구해 보자.
함수 map()으로 리스트 x의 세 요소인 x$a1, x$a2, x$a3에 mean()을 각각 적용하여 생성된 결과가 리스트로 출력되었다.
만일 결과를 리스트가 아닌 벡터로 출력하고자 한다면, 출력되는 벡터의 유형에 따라 map_lgl(), map_int(), map_dbl(), map_chr() 중 하나를 선택하면 된다.
예를 들어 위에 주어진 리스트 x를 구성하는 세 요소의 평균은 소수점이 있는 숫자이므로 함수 map_dbl()을 이용해야 숫자형 벡터로 출력된다.
함수 map()에는 생략부호(...) 변수가 포함되어 있어서 .f에 전달되는 부가적인 옵션을 추가할 수 있다.
데이터 프레임 airquality의 변수 Ozone, Solar.R, Wind, Temp의 평균을 계산하는 경우에,
함수 mean()에 결측값을 제외하는 옵션 na.rm = TRUE를 다음과 같이 추가할 수 있다.
airs |>
map_dbl(mean, na.rm = TRUE)
## Ozone Solar.R Wind Temp
## 42.129310 185.931507 9.957516 77.882353함수 map()에는 사용자 정의 함수를 입력해서 사용할 수 있다.
위에서 정의된 데이터 프레임 airs의 네 변수의 평균을 anonymous 함수로 계산해 보자.
airs |>
map_dbl(function(x) sum(x, na.rm = TRUE)/sum(!is.na(x)))
## Ozone Solar.R Wind Temp
## 42.129310 185.931507 9.957516 77.882353사용자 정의함수를 입력해서 사용할 수 있다는 것은 함수 lapply()에서도 가능한 것이다.
차이점은 함수 map()에서는 조금 더 간편한 방식으로 함수를 정의할 수 있다는 것이다.
Anonymous 함수는 반드시 function(x)로 시작하는데, 이것을 물결표(~)로 대치할 수 있고, 한 변수만이 사용되는 함수에서는 .x를 변수 대신 사용할 수 있다.
따라서 위의 예는 다음과 같이 작성할 수 있다.
airs |>
map_dbl(~ sum(.x, na.rm = TRUE)/sum(!is.na(.x)))
## Ozone Solar.R Wind Temp
## 42.129310 185.931507 9.957516 77.882353두 개의 변수가 사용되는 함수에서는 .x와 .y를 두 변수 대신 사용하고,
세 개 이상의 변수가 사용되는 함수에서는 ..1, ..2, ..3 등을 대신 사용하면 된다.
사용자 정의 함수를 사용하는 다른 예제로써 데이터 프레임 airquality의 변수 Ozone과 Solar.R의 상관계수를 월별로 계산해 보자.
우선 airquality를 함수 split()을 사용하여 월별로 구분한 결과를 리스트에 할당하고 이어서 함수 cor()로 이루어진 사용자 정의 함수를 map()에 다음과 같이 입력하면 된다.
airquality |>
split(airquality$Month) |>
map_dbl(~ with(.x, cor(Ozone, Solar.R, use = "pairwise")))
## 5 6 7 8 9
## 0.2428635 0.7177528 0.4293259 0.5296827 0.1803730이 문제는 함수 map()을 사용하지 않고 패키지 dplyr의 함수 nest_by()를 사용하여 rowwise 데이터 프레임을 구성하는 방법으로도 해결할 수 있다.
함수 nest_by()로 생성된 데이터 프레임은 첫 번째 열은 그룹 변수인 Month이고,
두 번째 열은 나머지 변수로 구성된 리스트로서 이름이 data이다.
데이터 프레임의 한 열을 리스트로 구성하는 것은 매우 특이한 상황으로 보일 수 있으나, 자료 분석 과정을 상당히 간편하게 만들 수 있는 대단히 뛰어난 아이디어라고 하겠다.
airquality |>
nest_by(Month)
## # A tibble: 5 × 2
## # Rowwise: Month
## Month data
## <int> <list<tibble[,5]>>
## 1 5 [31 × 5]
## 2 6 [30 × 5]
## 3 7 [31 × 5]
## 4 8 [31 × 5]
## 5 9 [30 × 5]이제 rowwise 데이터 프레임의 특성을 활용하여 각 행별로 data에 있는 두 변수의 상관계수를 구해보자.
airquality |>
nest_by(Month) |>
summarise(rho = with(data, cor(Ozone, Solar.R, use = "pairwise")))
## # A tibble: 5 × 2
## # Groups: Month [5]
## Month rho
## <int> <dbl>
## 1 5 0.243
## 2 6 0.718
## 3 7 0.429
## 4 8 0.530
## 5 9 0.180함수 map()의 .f 위치에 함수 대신 문자나 숫자 또는 리스트가 입력되면, 특정 요소를 선택하는 일종의 인덱싱이 이루어진다.
예를 들어 다음의 리스트 df1을 구성하고 있는 세 벡터의 두 번째 요소를 선택해 보자.
함수 map()에 숫자가 입력되면 선택할 위치를 지정하는 것으로써, 리스트 df1을 구성하는 각 벡터의 두 번째 요소를 선택하게 된다.
이번에는 문자를 입력하여 특정 요소를 선택하는 예제를 살펴보자.
예를 들어 \(N(-1,1)\) 과 \(N(1,1)\) 에서 각각 발생시킨 5개의 난수를 함수 summary()에 입력하여 계산된 요약통계량 값을 리스트에 할당해 보자.
set.seed(123)
df2 <- list(x1 = rnorm(n = 5, mean = -1), x2 = rnorm(n = 5, mean = 1)) |>
map(summary)
df2
## $x1
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -1.5605 -1.2302 -0.9295 -0.8064 -0.8707 0.5587
##
## $x2
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -0.2651 0.3131 0.5543 0.9557 1.4609 2.7151리스트 df2의 각 요소에서 "Mean"으로 이름이 붙여진 자료를 선택해 보자.
즉, 두 종류 자료에 대한 요약 통계량을 각각 계산하고, 그 중 평균값을 추출하는 작업이 된다.
선택된 자료가 df2를 구성하고 있는 벡터들의 네 번째 자료이므로 map_dbl(df2, 4)를 실행해도 같은 결과를 얻을 수 있다.
함수 map()은 하나의 리스트(혹은 벡터)의 각 구성요소에 특정 함수를 반복 적용시킬 때 사용되는 함수이다.
만일 두 개의 리스트(혹은 벡터)를 입력 변수로 하여 특정 함수를 반복 적용시켜야 하는 경우가 있다면 map2()가 사용될 수 있다.
기본적인 사용법은 map2(.x, .y, .f, ...)이며, .x와 .y는 두 개의 입력 리스트(혹은 벡터)로서 길이가 같아야 한다.
길이가 1인 벡터의 경우에만 순환법칙이 적용된다.
정규분포에서 난수를 발생시키되 \(N(-5, 2^{2})\) 과 \(N(5, 1^{2})\) 의 경우와 같이 평균과 표준편차가 모두 다른 경우를 생각해 보자.
이 경우에는 -5와 5가 입력된 벡터 mu를 .x에, 2와 1이 입력된 벡터 sigma를 .y에 지정하여 map2()에 입력하고 이어서 rnorm()을 입력하면 된다.
set.seed(123)
map2(.x = mu, .y = sigma, rnorm, n = 5)
## $x1
## [1] -6.120951 -5.460355 -1.882583 -4.858983 -4.741425
##
## $x2
## [1] 6.715065 5.460916 3.734939 4.313147 4.554338결과는 리스트로 출력되는데, 만일 결과를 데이터 프레임으로 출력하고자 한다면 map2()의 결과를 함수 list_cbind()에 입력하면 된다.
함수 list_cbind()는 각 요소가 데이터 프레임인 리스트를 입력하면, 각 요소들을 열 단위로 통합한 데이터 프레임을 출력한다.
따라서 map2()를 실행해서 출력된 리스크의 각 요소를 먼저 데이터 프레임으로 변환시키고, 이어서 list_cbind()에 입력해야 한다.
set.seed(123)
map2(.x = mu, .y = sigma, rnorm, n = 5) |>
map(as.data.frame) |>
list_cbind()
## .x[[i]] .x[[i]]
## 1 -6.120951 6.715065
## 2 -5.460355 5.460916
## 3 -1.882583 3.734939
## 4 -4.858983 4.313147
## 5 -4.741425 4.554338함수 map()의 경우에도 동일한 방식을 적용하면 결과를 데이터 프레임으로 출력할 수 있다.
7.7 연습문제
1. 데이터 프레임 airquality 에서 숫자형 변수의 요약 통계량을 월별로 계산하고자 한다
- 변수
Ozone의 월별 평균값을 다음과 같이 나타내 보자.
## 5 6 7 8 9
## 23.61538 29.44444 59.11538 59.96154 31.44828- 변수
Ozone의 월별 평균, 표준편차와 측정된 날수를 다음의 형식으로 나타내 보자.
## 5 6 7 8 9
## Mean 23.61538 29.44444 59.11538 59.96154 31.44828
## Sd 22.22445 18.20790 31.63584 39.68121 24.14182
## N 26.00000 9.00000 26.00000 26.00000 29.00000- 변수
Ozone의 월별 평균, 표준편차와 측정된 날수를 다음의 형식으로 나타내 보자.
## # A tibble: 5 × 4
## Month Mean Sd N
## <chr> <dbl> <dbl> <dbl>
## 1 5 23.6 22.2 26
## 2 6 29.4 18.2 9
## 3 7 59.1 31.6 26
## 4 8 60.0 39.7 26
## 5 9 31.4 24.1 292. 데이터 프레임 iris를 구성하고 있는 변수들의 유형을 파악하여 유형별로 적절한 요약통계를 계산해 보자
- 함수
map()을 사용하여iris변수들의 유형을 파악하고 다음과 같이 벡터로 출력해 보자.
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## "numeric" "numeric" "numeric" "numeric" "factor"- 함수
map2()을 사용하여 변수의 유형이numeric인 경우에는 평균을 계산하고, 유형이factor인 경우에는 범주의 개수를 계산하여 다음과 같이 출력해 보자.
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 5.843333 3.057333 3.758000 1.199333 3.0000003. 패키지 stringr의 fruit은 80 종류 과일 이름으로 구성된 문자형 벡터이다.
- 문자열을 구성하고 있는 개별 모음(“a”, “e”, “i”, “o”, “u”) 및 모음 전체의 개수를 계산하는 함수를 정의해 보자. 예를 들어 작성된 함수가
n_vowel()이라 하면, “apple”를n_vowel()입력하면 다음의 결과가 출력되도록 하자.
- 앞 문제에서 정의된 함수를 이용하여
fruit에 있는 모든 과일 이름을 구성하고 있는 개별 모음 및 모음 전체의 개수를 계산해서, 결과를 데이터 프레임 형태로 출력해 보자. 단, 데이터 프레임의 첫 번째 열에는 해당 과일 이름이 들어가고, 모음 전체의 개수가 많은 과일이 먼저 나타나도록 정렬해서 다음과 같이 출력해 보자.
## # A tibble: 80 × 7
## fruit a e i o u total
## <chr> <int> <int> <int> <int> <int> <int>
## 1 purple mangosteen 1 3 0 1 1 6
## 2 blood orange 1 1 0 3 0 5
## 3 cantaloupe 2 1 0 1 1 5
## 4 passionfruit 1 0 2 1 1 5
## # ℹ 76 more rows4. 패키지 MASS에 있는 데이터 프레임 Cars93는 1993년 미국에서 판매된 93대 자동차에 대한 27개 변수로 이루어진 자료이다.
각 변수의 요약 통계량 값을 계산하려는데, 숫자형 변수이면 평균을 계산하고, 요인이면 범주의 개수를 계산하려고 한다.
Cars93의 변수 중 숫자형 변수만을 선택한 데이터 프레임cars_1을 생성하고, 요인만을 선택한 데이터 프레임cars_2를 생성해 보자.for루프를 사용하여cars_1에 있는 모든 변수의 평균값을 계산해서 다음과 같이 출력해 보자.
## Min.Price Price Max.Price MPG.city
## 17.125806 19.509677 21.898925 22.365591
## MPG.highway EngineSize Horsepower RPM
## 29.086022 2.667742 143.827957 5280.645161
## Rev.per.mile Fuel.tank.capacity Passengers Length
## 2332.204301 16.664516 5.086022 183.204301
## Wheelbase Width Turn.circle Rear.seat.room
## 103.946237 69.376344 38.956989 27.829670
## Luggage.room Weight
## 13.890244 3072.903226for루프를 사용하여cars_2에 있는 모든 변수의 범주의 개수를 함수nlevels()로 계산해서 다음과 같이 출력해 보자.
## Manufacturer Model Type AirBags DriveTrain
## 32 93 6 3 3
## Cylinders Man.trans.avail Origin Make
## 6 2 2 93for루프로 실행한 작업을 함수map()으로 다시 실행해서 동일한 결과를 얻어 보자.
5. 입력된 자료가 숫자형 벡터이면 히스토그램을 작성하고, 요인이면 막대그래프를 작성하는 사용자 정의함수를 작성해 보자.
함수 이름은 my_plot()으로 하자.
- 패키지
ggplot2의 데이터 프레임mpg에 있는 변수displ을 함수my_plot()에 입력해서 다음과 같은 히스토그램을 작성해 보자. 구간의 개수는 15개, 막대의 색은 “midnightblue”로 지정한다.
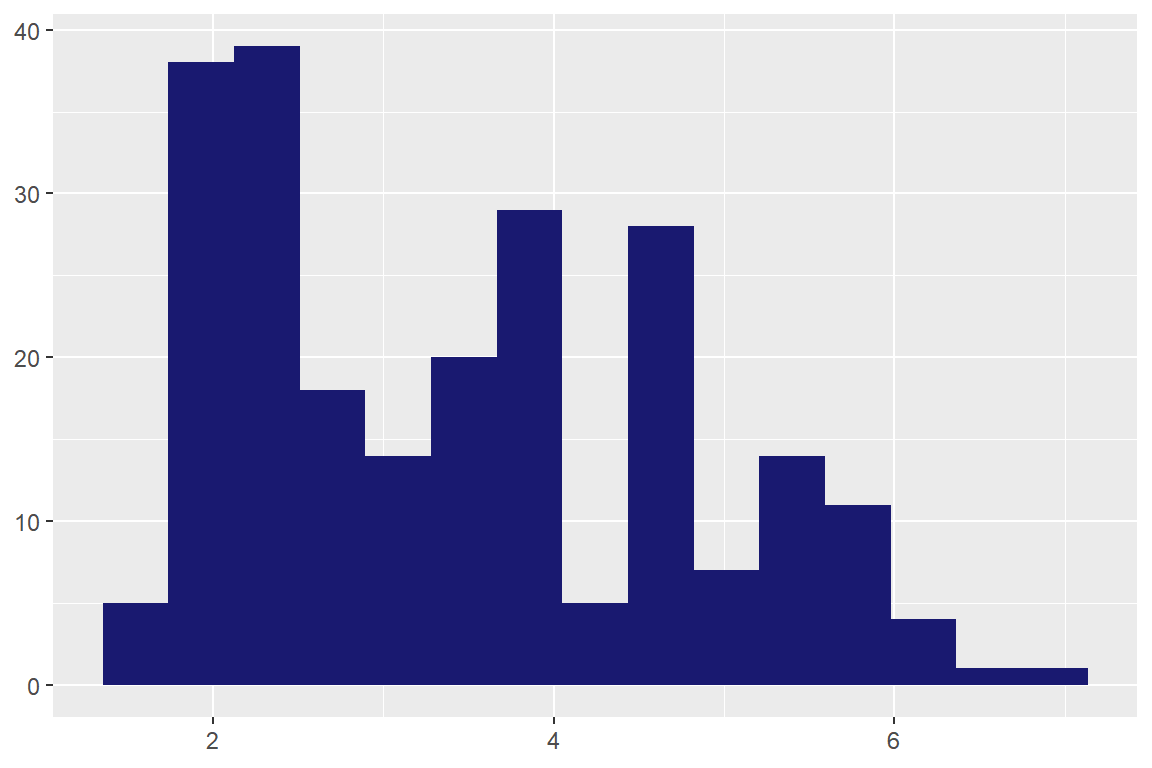
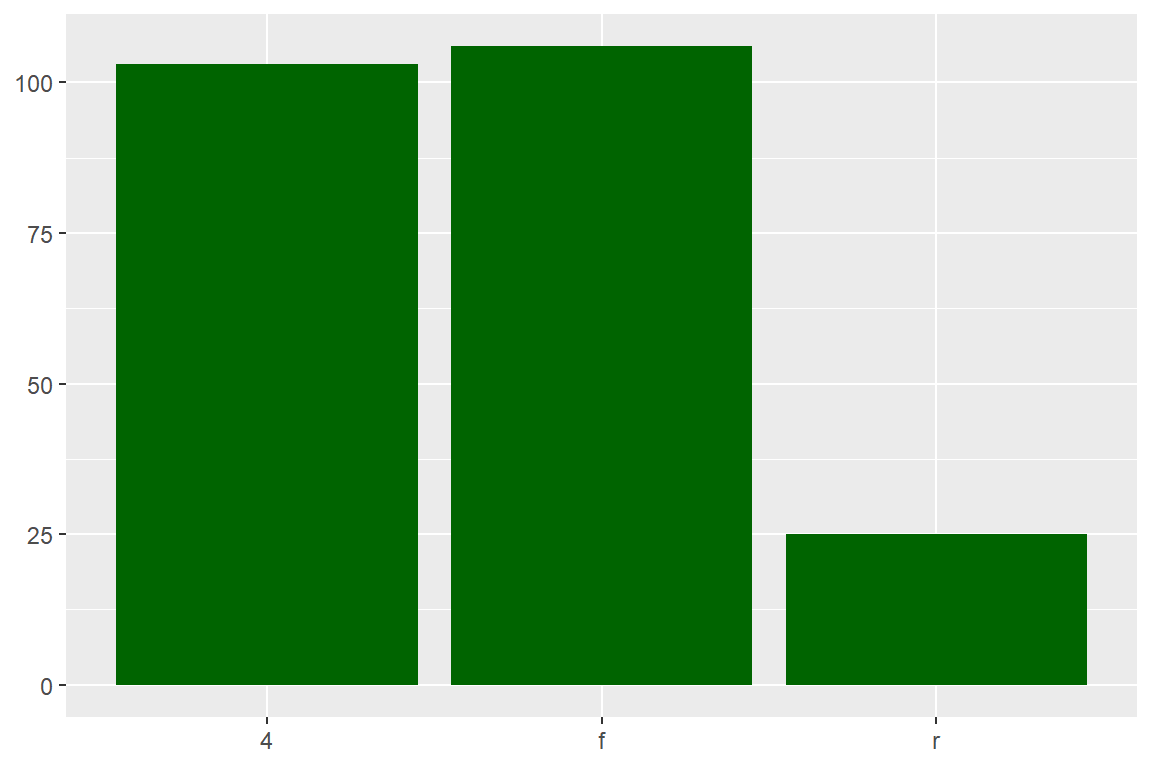
- 데이터 프레임
mpg에 있는 변수drv를 함수my_plot()에 입력해서 다음과 같은 막대그래프를 작성해 보자. 막대의 색은 “darkgreen”으로 지정한다.
6. 데이터 프레임을 입력 변수로 하는 함수를 작성하고자 한다.
- 입력된 데이터 프레임을 구성하고 있는 변수 중 숫자형 변수가 아닌 변수의 위치를 출력해 주는 함수를 작성해 보자. 작성된 함수의 이름을
cat_position이라고 한다면, 함수의 실행 예제로 데이터 프레임mpg와iris를 각각 입력한 결과는 다음과 같다. 즉,mpg의 첫 번째, 두 번째, 여섯 번째, 일곱 번째, 열 번째, 열한 번째 변수는 숫자형 변수가 아니라는 것이고,iris의 다섯 번째 변수는 숫자형이 아니라는 것이다.
- 입력된 데이터 프레임의 숫자형 변수에 대해 사용자가 지정한 요약 통계를 계산하는 함수를 작성해 보자. 작성된 함수의 이름을
num_summary라고 한다면, 함수의 실행 예제로iris와mean을 입력한 결과,iris를Species에 대해 그룹화한 데이터 프레임과mean을 입력한 결과, 그리고airquality에서 처음 네 변수만 선택한 데이터 프레임과mean을 입력한 결과는 각각 다음과 같다.
num_summary(iris, mean)
## Sepal.Length Sepal.Width Petal.Length Petal.Width
## 1 5.843333 3.057333 3.758 1.199333