3 장 데이터 입력
2장에서는 다양한 R 데이터 객체에 대해 살펴보았다. 지금부터는 모든 통계분석 및 그래프 작성의 첫 단계라고 할 수 있는 데이터 입력 방법에 대해 살펴보자. R은 텍스트 파일, 다른 통계 소프트웨어 전용 데이터 파일, Excel 파일 및 HTML 테이블 등 다양한 유형의 데이터 파일을 비교적 간단하게 불러올 수 있다.
3.1 텍스트 파일 불러오기: 패키지 readr 함수의 활용
많은 경우에 데이터 파일은 텍스트 파일의 형태로 저장되어 있다. 통계 데이터 세트는 행과 열의 2차원 형태로 구성되는데, 입력 형식은 매우 다양할 수 있다. 즉, 각각의 자료들이 빈칸으로 구분된 경우, 콤마로 구분된 경우, 고정 포맷 구조로 구성된 경우 등이 있게 된다. 따라서 이렇게 각기 다른 구성 형식의 텍스트 파일을 불러오는데 적합한 함수가 필요한 것이다.
외부 텍스트 파일을 불러오는 작업은 base R 함수인 read.table() 또는 read.csv()로 할 수 있으나, 크기가 큰 텍스트 파일을 불러와야 하는 경우에는 시간이 많이 걸린다는 문제가 있다. 이 절에서는 tidyverse에 속한 패키지 readr의 함수를 사용하여 효율적으로 텍스트 파일을 불러오는 방법을 살펴보겠다. 패키지 readr에는 텍스트 파일의 구성 형식에 맞추어 사용할 수 있는 다양한 함수가 마련되어 있다. 각각의 자료들이 하나 이상의 빈 칸으로 구분된 경우에는 read_table(), 콤마로 구분된 경우에는 함수 read_csv(), 탭으로 구분된 경우에는 함수 read_tsv(), 그 외 다른 형태의 구분자로 구분된 경우는 함수 read_delim()을 사용할 수 있으며, 고정된 포맷 구조를 갖는 경우에는 함수 read_fwf()을 사용하여 자료를 불러올 수 있다.
이 함수들은 불러올 파일의 경로를 포함한 파일 이름이 첫 번째 입력 요소가 된다. 파일 이름이 .gz 또는 .zip 등으로 끝나는 압축 파일은 자동으로 압축을 해제하고 자료를 불러온다. 또한 http://, https://, ftp://, ftps://로 시작되는 웹 서버에 있는 텍스트 파일도 불러올 수 있다.
3.1.1 함수 read_table()로 데이터 파일 불러오기
자료들이 하나 이상의 빈칸으로 구분된 경우에는 read_table()를 사용하여 파일을 불러올 수 있다.
1) 데이터 파일의 첫 줄에 변수 이름이 입력되어 있는 경우
예를 들어 파일 data2_1.txt에 세 변수의 자료가 다음과 같이 있다고 하자.

이런 경우에는 함수 read_table()에 파일의 위치와 함께 파일의 이름만 입력하면 된다.
read_table("https://raw.githubusercontent.com/yjyjpark/R-and-statistical-analysis/master/Data/data2_1.txt")
##
## ── Column specification ──────────────────────────────────────────────────────────────────────────────────────────
## cols(
## age = col_double(),
## gender = col_character(),
## income = col_double()
## )
## # A tibble: 4 × 3
## age gender income
## <dbl> <chr> <dbl>
## 1 24 M 2000
## 2 35 F 3100
## 3 28 F 3800
## 4 21 F 2800패키지 readr에 속한 함수들은 각 변수의 유형을 스스로 파악한다. 각 변수마다 처음 1000개의 자료를 읽고 정해진 규칙에 의하여 문자형, 정수형, 숫자형, 논리형 등으로 유형을 결정한다. 스스로 자료의 유형을 파악한 경우에는 각 변수별로 파악된 결과를 출력한다.
각 변수의 유형은 사용자가 직접 선언할 수도 있는데, 가장 간단한 방법은 입력 요소 col_types에 변수의 유형을 나타내는 문자를 변수가 입력된 순서대로 나열하여 지정하는 것이다. 자료의 유형을 나타내는 문자에는 c(문자형), i(정수형), d(실수형), n(숫자형), l (논리형), f(요인), D(날짜) 등이 있다. 예를 들어 파일 data2_1.txt의 경우에는 다음과 같이 자료의 유형을 선언하여 자료를 불러올 수 있다.
read_table("https://raw.githubusercontent.com/yjyjpark/R-and-statistical-analysis/master/Data/data2_1.txt",
col_types = "dcd")
## # A tibble: 4 × 3
## age gender income
## <dbl> <chr> <dbl>
## 1 24 M 2000
## 2 35 F 3100
## 3 28 F 3800
## 4 21 F 28002) 데이터만 파일에 입력되어 있는 경우
첫 줄에 변수 이름이 입력되어 있지 않은 데이터 파일도 많이 있다. 예를 들어 파일 data2_2.txt에 세 변수에 대한 데이터가 다음과 같이 있다고 하자.

이런 경우에는 입력 요소 col_names에 FALSE를 지정하거나 변수 이름을 나타내는 문자형 벡터를 지정해야 한다. 아무것도 지정하지 않으면 데이터 파일의 첫 줄에 입력된 자료가 각 변수의 이름으로 사용되는 오류가 발생한다. FALSE를 지정한 경우에 변수 이름은 X1, X2, X3 등이 된다.
read_table("https://raw.githubusercontent.com/yjyjpark/R-and-statistical-analysis/master/Data/data2_2.txt",
col_names = FALSE)
## # A tibble: 4 × 3
## X1 X2 X3
## <dbl> <chr> <dbl>
## 1 24 M 2000
## 2 35 F 3100
## 3 28 F 3800
## 4 21 F 2800read_table("https://raw.githubusercontent.com/yjyjpark/R-and-statistical-analysis/master/Data/data2_2.txt",
col_names = c("age", "gender", "income"))
## # A tibble: 4 × 3
## age gender income
## <dbl> <chr> <dbl>
## 1 24 M 2000
## 2 35 F 3100
## 3 28 F 3800
## 4 21 F 28003) 데이터 파일에 주석이 입력된 경우
데이터 파일에 주석이 있는 경우, 해당 행을 무시하기 위해서는 주석이 시작됨을 나타내는 기호를 입력 요소 comment에 지정하면 된다. 만일 기호 #을 주석 기호로 사용했다면 comment = "#"을 입력하면 된다. 또한 만일 주석이 데이터 파일의 처음 몇 개 행에 입력되어 있다면, 입력 요소 skip을 사용하여 해당되는 처음 몇 개 행을 읽지 않고 그냥 넘기는 방법을 사용할 수도 있다.

파일 data2_3.txt의 처음 세 줄이 # 기호로 시작되는 주석이 입력되어 있다. 이 파일을 두 가지 방법을 사용해서 불러와 보자.
read_table("https://raw.githubusercontent.com/yjyjpark/R-and-statistical-analysis/master/Data/data2_3.txt",
comment = "#")
## # A tibble: 4 × 3
## x1 x2 x3
## <dbl> <dbl> <dbl>
## 1 24 1 2000
## 2 35 0 3100
## 3 28 0 3800
## 4 21 0 2800read_table("https://raw.githubusercontent.com/yjyjpark/R-and-statistical-analysis/master/Data/data2_3.txt",
skip = 3)
## # A tibble: 4 × 3
## x1 x2 x3
## <dbl> <dbl> <dbl>
## 1 24 1 2000
## 2 35 0 3100
## 3 28 0 3800
## 4 21 0 28004) 데이터 파일에 결측값이 NA가 아닌 다른 기호로 입력된 경우
데이터에 결측값이 있는 것은 당연한 것으로 봐야 한다. R에서는 결측값을 NA로 표시하기 때문에 데이터에 결측값이 있다면 해당되는 자리에 NA를 입력해야 한다. 그러나 경우에 따라서 결측값이 다른 숫자나 문자 혹은 기호로 데이터 파일에 입력될 수도 있는데, 예를 들어 SAS의 경우 결측값은 점(.)으로 표시한다. 이렇듯 다른 기호로 결측값이 입력된 경우 에는 옵션 na에 해당 기호를 지정해 주어야 한다. 만일 결측값이 점(.)으로만 입력되어 있다면 na = "."으로 지정하면 되지만 NA와 점(.)이 모두 결측값을 나타내는 기호로 사용되었다면 na = c(".", "NA")로 두 기호를 모두 지정해야 한다.

파일 data2_4.txt에는 NA와 점(.)이 모두 결측값을 나타내는 기호로 사용되어 있다. 이 파일을 옵션 na를 사용해서 불러 보자. na = "."로 점(.)만을 결측값으로 지정하면, income 변수의 네 번째 자료인 NA는 결측값이 아닌 문자형 자료로 인식된다. 따라서 변수 income의 유형은 숫자형이 아닌 문자형이 된다.
read_table("https://raw.githubusercontent.com/yjyjpark/R-and-statistical-analysis/master/Data/data2_4.txt",
na = ".")
## # A tibble: 4 × 3
## age gender income
## <dbl> <chr> <chr>
## 1 24 M 2000
## 2 NA F 3100
## 3 28 <NA> 3800
## 4 21 F NAna = c(".", "NA")로 두 기호를 모두 결측값으로 지정해서 다시 불러 보자.
read_table("https://raw.githubusercontent.com/yjyjpark/R-and-statistical-analysis/master/Data/data2_4.txt",
na = c(".", "NA"))
## # A tibble: 4 × 3
## age gender income
## <dbl> <chr> <dbl>
## 1 24 M 2000
## 2 NA F 3100
## 3 28 <NA> 3800
## 4 21 F NA- 함수
file.choose()
외부 파일을 R로 불러오는 과정에서 파일이 저장되어 있는 폴더의 정확한 위치를 잊는 경우가 가끔 있다. 혹은 정확하다고 생각되는 파일의 경로를 입력했는데도 파일을 열 수 없다는 오류가 발생하는 경우도 있다.
이런 경우에 함수 file.choose()를 이용하면 굳이 윈도우 파일 탐색기를 이용하여 파일의 위치를 다시 확인하지 않고도 파일에 접근할 수 있다.
예를 들어 함수 read_table() 등에 파일의 위치와 더불어 파일 이름을 입력하는 대신 read_table(file.choose())를 실행하면 탐색기 창이 나타나서 접근하고자 하는 파일을 쉽게 찾을 수 있다.
3.1.2 함수 read_csv()로 CSV 데이터 파일 불러오기
CSV(Comma Separated Values) 파일이란 각 자료들이 콤마로 구분된 형식의 데이터 파일을 의미한다. Excel을 포함하는 많은 소프트웨어들이 CSV 형식의 데이터 파일을 읽어 올 수도 있고 작업결과를 CSV 형식으로 저장할 수도 있기 때문에 자주 사용되는 형식의 데이터 파일이라고 하겠다.

파일 data3_1.txt에는 자료들이 콤마로 구분되어 있고, 첫 줄에는 변수 이름이 입력되어 있다고 하자. 이 경우에는 read_csv()에 파일의 위치를 포함한 이름을 입력하면 파일을 불러올 수 있다.
read_csv("https://raw.githubusercontent.com/yjyjpark/R-and-statistical-analysis/master/Data/data3_1.txt")
## # A tibble: 4 × 3
## `var 1` `var 2` `var 3`
## <dbl> <chr> <dbl>
## 1 24 M 2000
## 2 35 F 3100
## 3 28 F 3800
## 4 21 F 2800함수 read_csv()로 생성된 tibble의 변수 이름이 backtick(`) 기호로 감싸져 있는 것을 볼 수 있다.
R에서 변수 이름은 반드시 문자로 시작해야 하며, 중간에 빈칸이 없어야 하는 등의 규칙이 있는데,
이러한 규칙에 어긋난 문자열이라도 tibble에서는 backtick 기호로 감싸서 정상적인 변수 이름으로 사용하고 있음을 보여주고 있다. Backtick 기호는 키보드에서 tab 키 바로 위에 있는 것이며, 인용부호와는 다른 기호이다.
함수 read_table()에서 살펴보았던 col_types, col_names, na, comment, skip은 read_csv()에서도 동일하게 작동되는 요소들이다. 예를 들어 data3_2.txt에 다음과 같이 자료가 입력되어 있다고 하자. 첫 줄에 주석이 있고, 결측값이 기호 NA와 점(.)으로 표시되어 있으며, 변수 이름은 입력되지 않았다.

이제 각 변수의 유형을 스스로 파악하게 해 보자.
read_csv("https://raw.githubusercontent.com/yjyjpark/R-and-statistical-analysis/master/Data/data3_2.txt",
col_names = FALSE,
comment = "#",
na = c(".", "NA"))
## Rows: 4 Columns: 3
## ── Column specification ──────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## dbl (2): X1, X3
## lgl (1): X2
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
## # A tibble: 4 × 3
## X1 X2 X3
## <dbl> <lgl> <dbl>
## 1 24 NA 2000
## 2 35 FALSE 3100
## 3 NA FALSE 3800
## 4 21 FALSE NA위 실행결과에서 자세하게 살펴볼 두 가지 중요한 사항이 있다. 첫 번째 사항은 CSV 파일에서는 자료를 입력하지 않고 빈칸으로 남겨두면 결측값으로 자동 처리된다는 것이다. 이것은 빈칸으로 남겨져 있는 변수 X1의 세 번째 자료가 NA로 처리된 것으로 알 수 있다. 각 자료가 콤마로 구분되어 있다는 것은 곧 각 자료의 입력 영역이 확보되어 있다는 것을 의미하기 때문에 빈칸으로 남겨진 영역을 결측값으로 자연스럽게 처리할 수 있는 것이다.
하지만 결측값을 빈칸으로 그냥 남겨두는 것은 좋은 작업 방식은 아니라고 할 수 있으며, 문제가 있을 수 있다는 경고 문구가 출력된다.
두 번째 사항은 변수 유형 파악에 오류가 발생할 수도 있으니 반드시 결과를 확인해야 한다는 것이다. 위 실행 결과에서 문자형 변수 X2의 유형이 논리형으로 파악됐는데, 이것은 변수 X2의 자료가 NA와 F로만 이루어져 있어서 F를 FALSE로 인식했기 때문이다. 이런 경우에는 변수 유형을 사용자가 직접 지정해야 한다.
3.1.3 함수 read_fwf()로 고정 포맷 구조를 갖는 데이터 파일 불러오기
데이터 파일 중에는 각 자료의 입력 위치가 고정되어 있는 경우가 있다. 예를 들어 파일 data4.txt에 다음과 같은 형식으로 세 변수의 데이터가 입력되어 있다고 하자.

변수 age는 1-2열, gender는 3열, income은 4-7열에 각각 입력되어 있다. 이러한 경우 각 자료들이 빈칸이나 콤마 등으로 구분되어 있어야만 사용할 수 있는 함수 read_table() 또는 read_csv() 등은 그야말로 무용지물이 된다. 이러한 형식의 파일을 읽기 위해서는 각 자료의 고정된 위치를 지정할 수 있어야 하는데, 함수 read_fwf()에 바로 그러한 기능이 있다. 고정된 위치 지정은 입력 요소 col_positions에 함수 fwf_widths() 또는 fwf_positions()를 연결하는 것이다. 각 변수의 자료가 입력되는 영역의 폭으로 위치를 지정하는 것은 fwf_widths(widths, col_names)로 하면 되고, 각 변수의 시작 열과 끝 열을 지정해서 자료의 위치를 나타내기 위해서는 fwf_positions(start, end, col_names)로 하면 된다. 옵션 col_names를 생략하면 변수 이름은 X1, X2, X3 등으로 지정된다.
이제 data4.txt를 읽어보자. fwf_widths()에 widths=c(2,1,4)를 지정하면 첫 번째 변수 age는 두 개의 열, 두 번째 변수 gender는 한 개의 열, 마지막 변수 income은 네 개의 열을 차지하고 있다는 것이다.
read_fwf("https://raw.githubusercontent.com/yjyjpark/R-and-statistical-analysis/master/Data/data4.txt",
col_positions = fwf_widths(widths = c(2, 1, 4),
col_names = c("age", "gender", "income")))
## # A tibble: 4 × 3
## age gender income
## <dbl> <chr> <dbl>
## 1 24 M 2000
## 2 35 F 3100
## 3 28 F 3800
## 4 21 F 2800fwf_positions()에 start=c(1,3,4)와 end=c(2,3,7)을 지정하면 첫 번째 변수 age는 1~2열에, 두 번째 변수 gender는 3열에, 마지막 변수 income은 4~7열에 입력되어 있다는 것을 나타낸다.
read_fwf("https://raw.githubusercontent.com/yjyjpark/R-and-statistical-analysis/master/Data/data4.txt",
col_positions = fwf_positions(start = c(1, 3, 4),
end = c(2, 3, 7),
col_names = c("age", "gender", "income")))
## # A tibble: 4 × 3
## age gender income
## <dbl> <chr> <dbl>
## 1 24 M 2000
## 2 35 F 3100
## 3 28 F 3800
## 4 21 F 2800- RStudio 메뉴에서 불러오기
외부 텍스트 파일을 불러오는 작업은 RStudio의 메뉴를 이용해서도 할 수 있다. 메인 메뉴 에서 File > Import Dataset > From Text (readr)… 을 선택하면 나타나는 별도의 창에서 필요한 사항을 선택하면 read_table() 혹은 read_csv() 등을 사용하여 파일을 불러오게 된다. 만일 base R 함수인 read.table() 혹은 read.csv() 등을 이용하고자 한다면 File > Import Dataset > From Text (base)…을 선택해서 불러올 수 있다. 또한 다음 절에서 살펴볼 Excel 파일이나, SAS 데이터 파일 등을 불러오는 작업도 File > Import Dataset의 하부 메뉴를 이용해서 할 수 있다.
- 데이터 프레임을 외부 텍스트 파일로 저장하기
R에서 생성되고 수정된 데이터 프레임을 외부 텍스트 파일로 저장시켜 다른 소프트웨어에서도 사용할 수 있도록 하는 것도 중요한 작업이다. 데이터 프레임을 외부 텍스트 파일로 저장하는 작업은 자료들을 어떤 기호로 구분할 것인지에 따라 패키지 readr의 함수 write_delim(), write_csv() 또는 write_tsv() 등을 사용할 수 있다. 자료들을 빈칸으로 구분하려면 write_delim(), 콤마로 구분하려면 write_csv(), 탭으로 구분하려면 write_tsv()를 사용하면 된다. 데이터 프레임을 외부 텍스트 파일로 저장하는 작업은 write.csv()와 같은 base R 함수로도 할 수 있다. Base R의 함수들은 데이터 프레임의 행 이름을 텍스트 파일의 첫 번째 열에 배치하고, 모든 문자 및 변수 이름에 인용부호를 붙이는 것이 디폴트인 반면에 패키지 readr의 함수들은 데이터 프레임의 행 이름을 절대 저장하지 않으며 인용 부호는 필요한 경우에만 사용된다. 또한 패키지 readr의 함수들의 실행 속도가 2배 정도 빠른 것으로 되어 있다.
Base 패키지인 datasets에 있는 데이터 프레임 women은 30대 미국 여성 15명의 몸무게와 키가 측정되어 있는 데이터 세트이다. 키는 인치 단위, 몸무게는 파운드 단위로 측정되었다. 데이터 프레임 women을 Data 폴더에 텍스트 파일로 저장하기 위해 다음 프로그램을 각각 실행해 보고 생성되는 텍스트 파일을 확인하기 바란다.
3.2 Excel 파일 불러오기
Excel에서 데이터를 만들고 가공하는 경우가 많기 때문에 Excel 스프레드시트에 있는 데이터를 R로 불러오는 것은 상당히 중요한 작업이 된다. Excel 파일을 R로 불러오는 방법에는 몇가지가 있는데, 그 중 tidyverse에 속한 패키지 readxl의 함수 read_excel()의 사용법을 살펴보자. 함수 read_excel()은 Excel 2003 이하 버전의 파일 형식인 xls 파일과 Excel 2007 이상 버전의 파일 형식인 xlsx 파일을 모두 불러올 수 있다. 다만 아직은 함수에 URL을 입력해서 웹 서버에 있는 Excel 파일을 직접 불러올 수는 없다.
예제 데이터로 폴더 Data에 있는 파일 data5.xlsx`에 다음과 같이 자료가 입력되어 있다고 하자. 자료는 첫 번째 시트에 입력되어 있다.

입력할 데이터가 있는 시트 번호를 지정하지 않으면, 디폴트로 첫 번째 시트의 데이터를 입력한다. 만일 다른 시트의 데이터를 입력하고자 한다면, 옵션 sheet에 시트 번호를 지정하면 된다.
library(readxl)
read_excel("Data/data5.xlsx")
## # A tibble: 5 × 3
## age gender income
## <dbl> <chr> <dbl>
## 1 24 M 2000
## 2 35 F 3100
## 3 28 F 3800
## 4 21 F 2800
## 5 31 M 3500시트의 전체 데이터 중 일부분만을 입력하고자 한다면, 옵션 range에 입력하고자 하는 데이터 범위 사각형의 왼쪽 위 모서리와 오른쪽 아래 모서리의 셀 번호를 지정하면 된다.
read_excel("Data/data5.xlsx", range = "A1:B5")
## # A tibble: 4 × 2
## age gender
## <dbl> <chr>
## 1 24 M
## 2 35 F
## 3 28 F
## 4 21 F- Excel 파일을 CSV 파일로 전환한 후 불러오기
함수 read_excel()을 사용하면 Excel 파일을 R로 불러오는 데에는 큰 문제가 없겠지만, 어떤 이유로 해서 Excel 파일을 직접 R로 불러올 수 없는 경우에 대안으로 사용할 수 있는 방법이다. Excel 파일을 CSV 파일로 전환하여 저장하는 방법은 Excel의 메인 메뉴에서 파일 > 다른 이름으로 저장을 선택한 후 CSV 파일 형식으로 저장하면 된다. 저장된 CSV 파일은 함수 read_csv()로 불러올 수 있다.
3.3 SAS 데이터 파일 불러오기
SAS는 범용 통계 소프트웨어로서 매우 두터운 사용자 층을 형성하고 있다. 따라서 SAS 전용 데이터 파일을 R로 불러오는 것도 중요한 작업이다. SAS 전용 데이터 파일을 R로 직접 불러오는 방법을 알아보자.
- 패키지
haven의 함수read_sas()로 SAS 전용 데이터 파일 불러오기
예를 들어 Data 폴더에 다음의 SAS 명령문으로 생성된 데이터 파일 data6.sas7bdat가 있다고 하자.
LIBNAME mysas 'D:\Data';
DATA mysas.data6;
INPUT age gender $ income;
CARDS;
24 M 2000
35 F 3100
28 F 3800
21 F 3500
31 M 3500
RUN;패키지 haven도 tidyverse 계열에 속하는 패키지이므로, 함수 read_sas()은 tibble을 생성한다.
library(haven)
read_sas("Data/data6.sas7bdat")
## # A tibble: 5 × 3
## age gender income
## <dbl> <chr> <dbl>
## 1 24 M 2000
## 2 35 F 3100
## 3 28 F 3800
## 4 21 F 3500
## 5 31 M 3500- SAS 전용 데이터 파일을 CSV 파일로 전환한 후 불러오기
SAS 전용 데이터 파일은 SAS의 PROC EXPORT를 사용하여 CSV 파일로 전환하여 저장할 수 있다. Excel의 경우처럼 R로 직접 불러오는 방법에 대한 대안으로 사용할 수 있다. SAS 전용 데이터 파일인 data6.sas7bdat을 CSV 파일인 data6.csv로 출력하는 SAS 명령문은 다음과 같다.
LIBNAME mysas 'D:\Data';
PROC EXPORT DATA=mysas.data6
OUTFILE='D:\Data\data6.csv'
DBMS=CSV;
RUN;패키지 haven에는 SPSS 데이터 파일과 Stata 데이터 파일을 불러올 수 있는 함수도 있다. SPSS 데이터 파일은 read_spss(), Stata DTA 파일은 read_stata()를 사용하면 어렵지 않게 불러올 수 있다.
3.4 HTML 테이블 불러오기
웹 페이지를 보다 보면 중요한 정보가 있는 HTML 테이블을 자주 만나게 되는데, 이 테이블에 있는 데이터를 R로 바로 불러들일 수 있다면 분석 과정에 큰 도움이 될 것이다. 문제는 웹 페이지에 있는 HTML 테이블이라는 것이 사람들에게 시각적으로 보여지는 측면이 강조되는 대상이어서 거기에 있는 정보를 ‘긁어모아’ 컴퓨터에 입력하는 것이 조금 복잡한 작업이 될 수 있다는 점이다. 그러나 패키지 rvest를 이용하면 비교적 간편하게 HTML 테이블의 데이터를 긁어모아 R에 입력시킬 수 있다.
패키지 rvest에서 HTML 테이블을 불러오는데 필요한 함수는 read_html()과 html_elements(), html_table()이다. 함수 read_html()은 원하는 HTML 테이블이 있는 웹 페이지를 읽어오는 데 사용된다. HTML 테이블의 내용은 <table> 태그 사이에 존재하기 때문에 <table> 노드(node)를 찾는 것이 다음 순서인데, 이 작업은 함수 html_elements()로 할 수 있다. 이어서 선택된 노드의 HTML 테이블 데이터를 R로 불러오는 작업은 함수 html_table()로 하게 된다.
\(\bullet\) 예제 1: Wikipedia 웹 페이지에 있는 HTML 테이블 데이터 불러오기
그림 3.1은 Wikipedia에서 “World population”을 검색하면 열리는 웹 페이지에 있는 “10 most densely populated countries”라는 제목의 HTML 테이블을 보여주고 있다. 검색은 2024-06-04에 실시된 것을 바탕으로 하고 있으며, 차후에 HTML 테이블의 배치가 변경되면 아래 예제 프로그램도 적절히 변경해야 할 것이다.
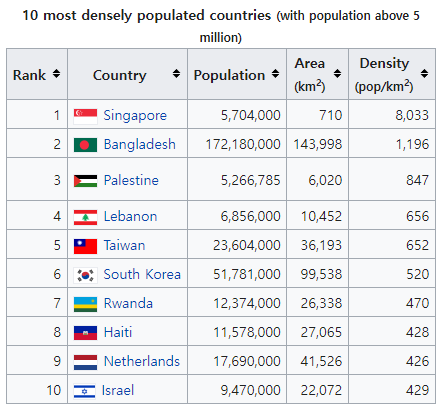
그림 3.1: 예제 1에서 사용된 HTML 테이블
원하는 웹 페이지의 URL을 함수 read_html()에 입력하여 얻은 결과에서 table 노드를 함수 html_elements()로 찾아보자. 함수 html_elements()는 결과를 리스트 형태로 출력한다.
library(rvest)
URL <- "https://en.wikipedia.org/wiki/World_population"
web <- read_html(URL)
tbl <- html_elements(web, "table")모두 30개의 table 노드가 발견되었고, 그 중 처음 6개의 내용을 출력해 보자.
head(tbl)
## {xml_nodeset (6)}
## [1] <table class="wikitable" style="text-align:center; float:right; clear:rig ...
## [2] <table class="wikitable">\n<caption>Current world population and latest p ...
## [3] <table class="box-Notice plainlinks metadata ambox ambox-notice" role="pr ...
## [4] <table class="wikitable sortable">\n<caption>Population by region (2020 e ...
## [5] <table class="sortable wikitable sticky-header static-row-numbers sort-un ...
## [6] <table class="wikitable" style="font-size:90%">\n<caption>World populatio ...함수 html_elements()의 결과로 생성된 리스트 객체인 tbl의 30개 구성요소 중 우리가 원하는 HTML 테이블에 해당되는 노드를 찾아서 함수 html_table()에 입력하면, 해당 테이블 데이터가 R로 입력된다. 문제는 몇 번째 노드가 우리가 원하는 테이블에 관한 것인지 알기가 어렵다는 점이다. 시행착오를 거치면, 원하는 테이블이 2023년 8월에는 8번째 노드에 있다는 것을 알 수 있었고, 따라서 html_table(tbl[8])을 실행하면 테이블의 데이터를 불러올 수 있다.
그러나 HTML 테이블이 많은 웹 페이지에서는 다른 체계적인 방법이 필요할 것이다.
웹 페이지에서 HTML 테이블을 체계적으로 찾는 방법 중 하나는 해당 테이블 노드의 XPath를 알아내는 것이다. XPath는 웹 문서에서 원하는 태그나 속성 등을 쉽게 찾기 위해 개발된 것으로 윈도우의 파일 경로와 비슷한 개념이라고 하겠다.
크롬 웹 브라우저를 대상으로 웹 페이지에서 원하는 HTML 테이블의 XPath를 알아내는 방법은 다음과 같다.
- 원하는 웹 페이지로 이동
- F12 키를 눌러서(또는
마우스 오른쪽 버튼 클릭 > 검사 클릭) 개발자 도구 실행. 창이 분리되며 오른쪽 창에 html 코드가 나타남. - Ctrl + F 키를 눌러서 나타난 찾기 창에
<table을 입력하고 찾기 실행 - 원하는 테이블에 해당되는 노드를 찾게 되면 그림 3.2에서와 같이 테이블이 하이라이트가 된다. 이어서 마우스 오른쪽 버튼을 클릭
- 나타난 별도 메뉴에서
Copy > Copy XPath를 클릭
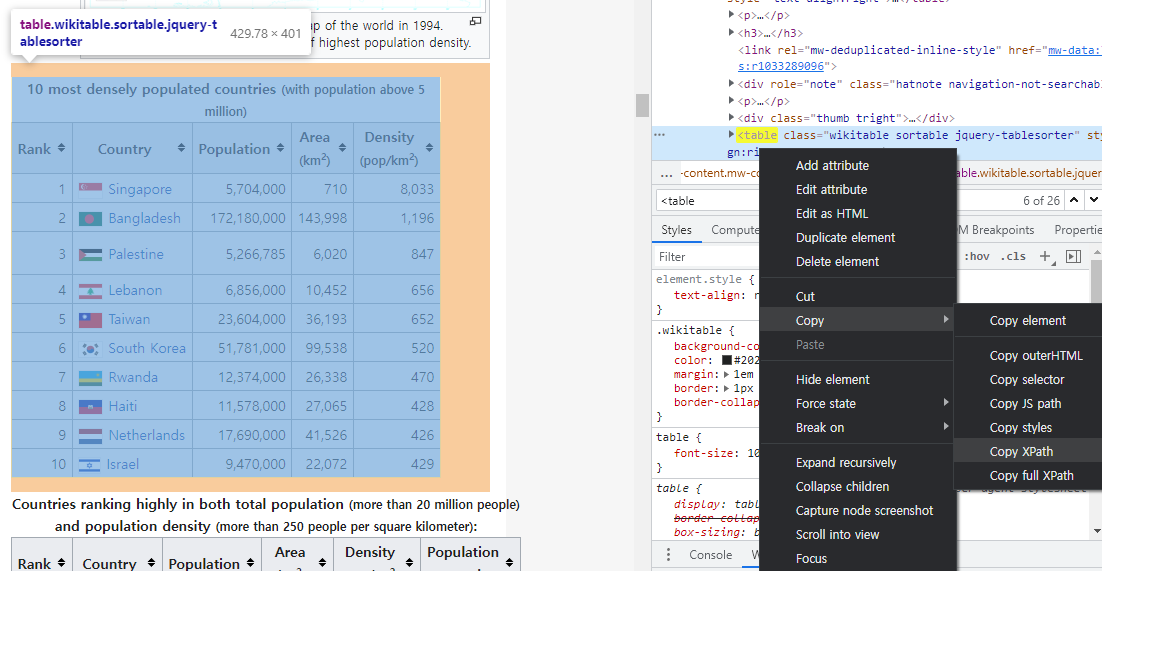
그림 3.2: 예제 1의 HTML 테이블 XPath 복사
원하는 HTML 테이블의 XPath의 값은 2023년 8월에 확인한 것으로는 //*[@id="mw-content-text"]/div[1]/table[7]이며, 이것을 함수 html_elements()안에 옵션 xpath에 지정하면 된다.
X_path <- '//*[@id="mw-content-text"]/div[1]/table[7]'
node_1 <- html_elements(web, xpath = X_path)
tbl_1 <- html_table(node_1)tbl_1
## [[1]]
## # A tibble: 10 × 5
## Rank Country Population `Area(km2)` `Density(pop/km2)`
## <int> <chr> <chr> <chr> <chr>
## 1 1 Singapore 5,921,231 719 8,235
## 2 2 Bangladesh 165,650,475 148,460 1,116
## 3 3 Palestine[note 3][101] 5,223,000 6,025 867
## 4 4 Taiwan[note 4] 23,580,712 35,980 655
## 5 5 South Korea 51,844,834 99,720 520
## 6 6 Lebanon 5,296,814 10,400 509
## 7 7 Rwanda 13,173,730 26,338 500
## 8 8 Burundi 12,696,478 27,830 456
## 9 9 Israel 9,402,617 21,937 429
## 10 10 India 1,389,637,446 3,287,263 423함수 html_table()로 생성된 객체 tbl_1은 하나의 데이터 프레임으로 구성된 리스트이다.
변수 이름을 수정하고 입력된 자료를 출력해 보자.
top_pop
## # A tibble: 10 × 5
## rank country pop area density
## <int> <chr> <chr> <chr> <chr>
## 1 1 Singapore 5,921,231 719 8,235
## 2 2 Bangladesh 165,650,475 148,460 1,116
## 3 3 Palestine[note 3][101] 5,223,000 6,025 867
## 4 4 Taiwan[note 4] 23,580,712 35,980 655
## 5 5 South Korea 51,844,834 99,720 520
## 6 6 Lebanon 5,296,814 10,400 509
## 7 7 Rwanda 13,173,730 26,338 500
## 8 8 Burundi 12,696,478 27,830 456
## 9 9 Israel 9,402,617 21,937 429
## 10 10 India 1,389,637,446 3,287,263 423변수 pop, area, density이 숫자가 아닌 문자형 벡터로 입력되었음을 알 수 있다. 이것은 숫자에 콤마가 함께 입력되어 있기 때문인데, 이제 변수 pop을 숫자형으로 변환하여 평균을 구해보자. 숫자형으로 변환하는 방법은 pop에 포함된 콤마를 2장에서 살펴본 함수 gsub()를 사용하여 제거하고, 이어서 함수 as.numeric()을 사용하여 유형을 숫자형으로 변환하면 된다.
top_pop |> print(n = 3)
## # A tibble: 10 × 5
## rank country pop area density
## <int> <chr> <dbl> <chr> <chr>
## 1 1 Singapore 5921231 719 8,235
## 2 2 Bangladesh 165650475 148,460 1,116
## 3 3 Palestine[note 3][101] 5223000 6,025 867
## # ℹ 7 more rows데이터 프레임 top_pop의 변수 pop이 숫자형으로 변환된 것을 확인할 수 있다.
이제 평균을 구해보자.
\(\bullet\) 예제 2: KBO 홈페이지 기록실에 있는 자료 불러오기
KBO 홈페이지의 기록실에 있는 자료를 불러와 보자. 자료를 불러온 시점은 2024-06-04이며, 내용은 KBO 정규 시즌 중 타자들의 팀 기록이다. 불러오고자 하는 HTML 테이블은 그림 3.3에서 볼 수 있다. 해당 웹 페이지에는 하나의 HTML 테이블만이 있기 때문에 굳이 XPath를 복사해야 할 필요는 없다. 한글이 포함된 HTML 테이블을 불러와 보자.
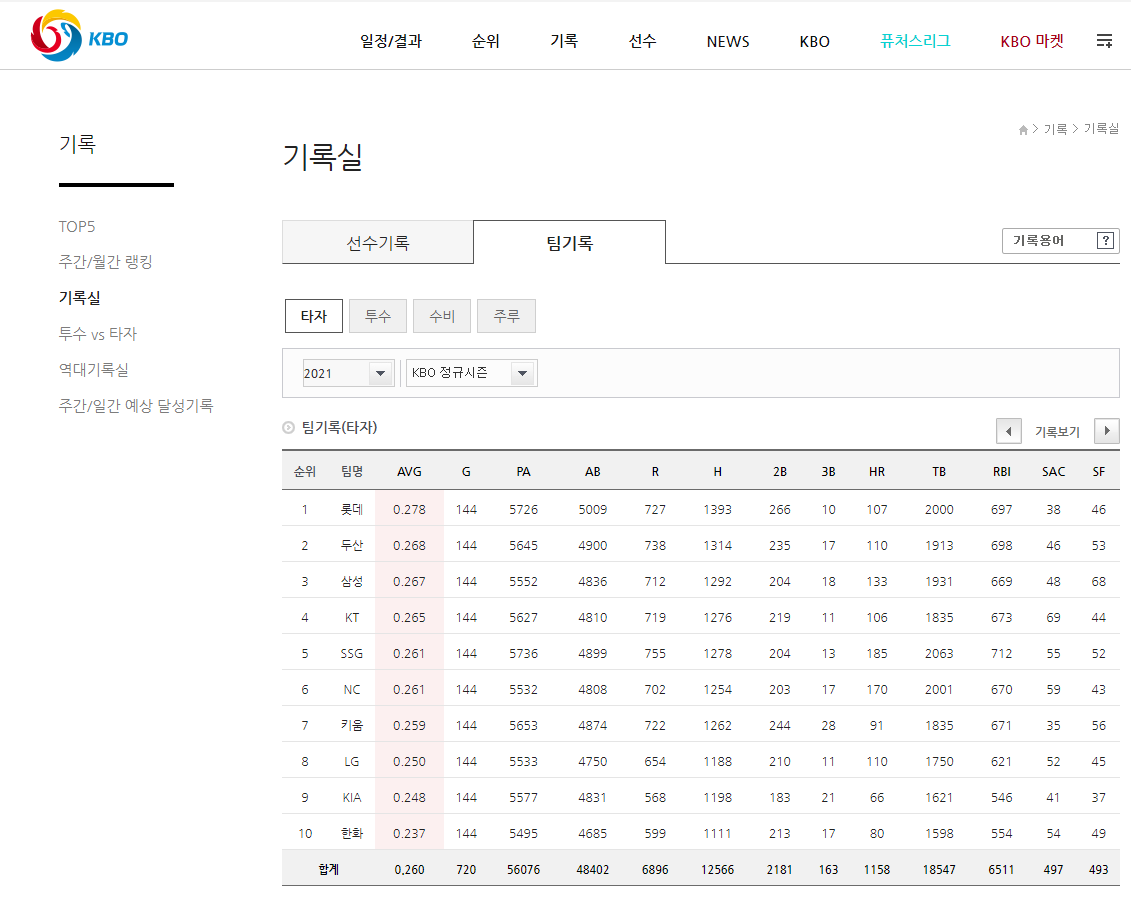
그림 3.3: 예제 2에서 사용된 HTML 테이블
R 버전 4.2.0부터 한글 인코딩이 UTF-8 방식으로 되어 있다면, locale 조정 없이 바로 불러올 수 있다.
URL_2 <- "https://www.koreabaseball.com/Record/Team/Hitter/Basic1.aspx"
web_2 <- read_html(URL_2)
node_2 <- html_elements(web_2, "table")
tbl_2 <- html_table(node_2)[[1]]합계가 들어간 마지막 행을 삭제하고, 결과를 출력해 보자.
tbl_2 <- tbl_2[-nrow(tbl_2),]
tbl_2
## # A tibble: 10 × 15
## 순위 팀명 AVG G PA AB R H `2B` `3B` HR TB RBI
## <chr> <chr> <dbl> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int>
## 1 1 KIA 0.292 58 2328 2054 331 599 100 9 64 909 315
## 2 2 LG 0.285 60 2419 2043 348 582 93 13 46 839 325
## 3 3 KT 0.278 58 2358 2063 325 573 94 5 59 854 301
## 4 4 두산 0.277 61 2380 2093 336 580 98 12 66 900 317
## 5 5 NC 0.273 58 2359 2015 308 551 92 6 59 832 300
## 6 6 롯데 0.272 56 2190 1963 268 534 101 16 42 793 251
## 7 7 삼성 0.27 58 2333 2024 293 546 94 6 58 826 280
## 8 8 SSG 0.266 58 2289 2012 294 536 83 6 57 802 281
## 9 9 키움 0.265 56 2190 1944 255 515 79 7 44 740 246
## 10 10 한화 0.264 57 2251 1965 298 519 89 8 55 789 285
## # ℹ 2 more variables: SAC <int>, SF <int>일반적으로 웹 페이지에 있는 HTML 테이블을 R로 불러온 후에도 실제 분석 데이터로 사용하기 위해서는 많은 추가 작업이 필요하게 된다.
3.5 연습문제
1. 다음은 Wikipedia에서 covid-19 관련 자료가 있는 웹 페이지(https://en.wikipedia.org/wiki/COVID-19_pandemic_by_country_and_territory)에 있는 HTML 테이블의 일부분이다.
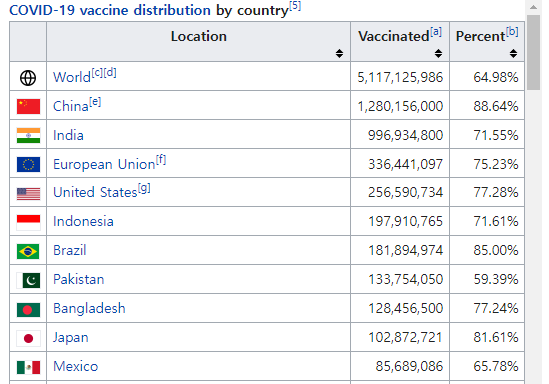
- R로 불러와서 tibble
ex3_1에 입력하고, 다음과 같이 출력해 보자.
ex3_1
## # A tibble: 223 × 4
## `` Location `Vaccinated[a]` `Percent[b]`
## <chr> <chr> <chr> <chr>
## 1 "" World[c][d] 5,631,262,551 70.61%
## 2 "" China[e] 1,310,292,000 91.89%
## 3 "" India 1,027,438,658 72.50%
## 4 "" European Union[f] 338,119,445 75.11%
## 5 "" United States[g] 270,227,181 81.39%
## 6 "" Indonesia 203,878,473 74.00%
## 7 "" Brazil 189,643,431 88.08%
## 8 "" Pakistan 165,567,890 70.21%
## 9 "" Bangladesh 151,507,159 88.50%
## 10 "" Japan 104,705,133 84.47%
## # ℹ 213 more rows- 자료가 없는
ex3_1의 첫 번째 변수를 제거하고, 세 번째 변수 Vaccinated[a]와 네 번째 변수 Percent[b]는 이름을Vaccinated와Percent로 변경하자. 또한 첫 번째 행과 자료가 잘못 입력된 마지막 행도 제거해 보자. 변경된 데이터 프레임의 처음 3개 행과 마지막 3개 행의 내용은 다음과 같다.
head(ex3_1, n = 3)
## # A tibble: 3 × 3
## Location Vaccinated Percent
## <chr> <chr> <chr>
## 1 China[e] 1,310,292,000 91.89%
## 2 India 1,027,438,658 72.50%
## 3 European Union[f] 338,119,445 75.11%tail(ex3_1, n = 3)
## # A tibble: 3 × 3
## Location Vaccinated Percent
## <chr> <chr> <chr>
## 1 Niue 1,650 102.23%
## 2 Pitcairn Islands 47 100.00%
## 3 North Korea 0 0.00%- 변수
Percent는 백신 접종률을 나타내는 변수이다. 백신 접종률이 95%를 초과하는 나라를 선택해서ex3_2에 입력하고, 다음과 같이 출력해 보자.
ex3_2
## # A tibble: 11 × 3
## Location Vaccinated Percent
## <chr> <dbl> <dbl>
## 1 Cuba 10805570 96.4
## 2 United Arab Emirates 9991089 100
## 3 Portugal 9791341 95.3
## 4 Qatar 2852178 106.
## 5 Macau 679703 97.8
## 6 Brunei 451149 100.
## 7 Gibraltar 42175 129.
## 8 Nauru 13106 103.
## 9 Tokelau 2203 116.
## 10 Niue 1650 102.
## 11 Pitcairn Islands 47 1002. 웹서버 https://raw.githubusercontent.com/yjyjpark/R-and-statistical-analysis/master/Data/에 있는 파일 ex3-2.csv에는 1993년 미국에서 판매된 93대 자동차의 생산 회사(Manufacturer)와 차량 모델 (Model) 의 최소 가격 (Min.Price) 및 최대 가격 (Max.Price)이 입력되어 있다.
- 파일
ex3-2.csv를 불러와서 데이터 프레임에 입력하고 다음과 같이 출력해 보자.
## # A tibble: 93 × 4
## Manufacturer Model Min.Price Max.Price
## <chr> <chr> <chr> <chr>
## 1 Acura Integra $12,900 $18,800.00
## 2 Acura Legend $29,200 $38,700.00
## 3 Audi 90 $25,900 $32,300.00
## # ℹ 90 more rows- 변수
Manufacturer와Model을 하나의 변수model로 통합하고 , 변수Min.Price와Max.Price의 평균으로 변수price를 생성해 보자. 이어서 두 변수model과price로 이루어진 데이터 프레임을 만들어 다음과 같이 출력해 보자
## # A tibble: 93 × 2
## model price
## <chr> <dbl>
## 1 Acura Integra 15850
## 2 Acura Legend 33950
## 3 Audi 90 29100
## # ℹ 90 more rows- 변수
price의 값이 가장 큰 자동차와 가장 작은 지동차의model값을 각각 구하고 두 자동차의price차이도 구해 보자
3. 다음은 Wikipedia에서 우리나라의 2012년 20개 주요 수출품목 자료가 있는 웹 페이지(https://en.wikipedia.org/wiki/List_of_exports_of_South_Korea) 에 있는 HTML 테이블의 일부분이다.
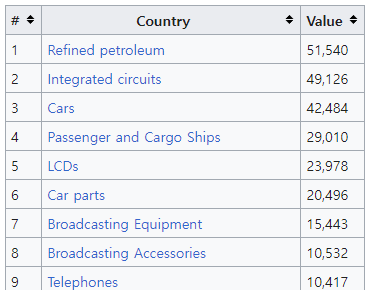
- HTML 테이블을 R로 불러와
export에 입력하고 출력해 보자.
export
## # A tibble: 20 × 3
## `#` Country Value
## <int> <chr> <chr>
## 1 1 Refined petroleum 51,540
## 2 2 Integrated circuits 49,126
## 3 3 Cars 42,484
## 4 4 Passenger and Cargo Ships 29,010
## 5 5 LCDs 23,978
## 6 6 Car parts 20,496
## 7 7 Broadcasting Equipment 15,443
## 8 8 Broadcasting Accessories 10,532
## 9 9 Telephones 10,417
## 10 10 Cyclic Hydrocarbons 8,791
## 11 11 Special Purpose Ships 8,117
## 12 12 Computers 6,340
## 13 13 Hot-Rolled Iron 6,288
## 14 14 Coated Flat-Rolled Iron 5,654
## 15 15 Semiconductor devices 5,210
## 16 16 Large Construction Vehicles 5,091
## 17 17 Polycarboxylic acids 4,833
## 18 18 Polyacetals 4,743
## 19 19 Machinery Having Individual Functions 4,621
## 20 20 Tires 4,614- 변수 이름을 다음과 같이
rank,item,value로 변경하자.
export |> print(n = 3)
## # A tibble: 20 × 3
## rank item value
## <int> <chr> <chr>
## 1 1 Refined petroleum 51,540
## 2 2 Integrated circuits 49,126
## 3 3 Cars 42,484
## # ℹ 17 more rows- 변수
value는 각 품목의 수출액이다. 각 품목의 수출액이 20개 전체 품목의 총 수출액에서 차지하는 비율을 나타내는 변수prop를 다음과 같이 생성해 보자.
export |> print(n = 5)
## # A tibble: 20 × 4
## rank item value prop
## <int> <chr> <dbl> <dbl>
## 1 1 Refined petroleum 51540 16.2
## 2 2 Integrated circuits 49126 15.5
## 3 3 Cars 42484 13.4
## 4 4 Passenger and Cargo Ships 29010 9.14
## 5 5 LCDs 23978 7.56
## # ℹ 15 more rows- 변수
prop의 값이 5 이상인 품목만을 선택해서 다음의 형태로 출력해 보자.
export_5
## # A tibble: 6 × 3
## item value prop
## <chr> <dbl> <chr>
## 1 Refined petroleum 51540 16.24%
## 2 Integrated circuits 49126 15.48%
## 3 Cars 42484 13.39%
## 4 Passenger and Cargo Ships 29010 9.14%
## 5 LCDs 23978 7.56%
## 6 Car parts 20496 6.46%- 변수
prop의 값이 5 이상인 품목의 평균 수출액을 계산해 보자.
4. 웹서버 https://raw.githubusercontent.com/yjyjpark/R-and-statistical-analysis/master/Data/에 있는 파일 airs.csv에는 1973년 5월 뉴욕시에서 측정된 공기의 질과 관련된 자료가 입력되어 있다.
- R로 불러와서 다음과 같이 출력해 보자.
airs
## # A tibble: 31 × 5
## Day Ozone Solar.R Wind Temp
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 41 190 7.4 67
## 2 2 36 118 8 72
## 3 3 12 149 12.6 74
## 4 4 18 313 11.5 62
## 5 5 NA NA 14.3 56
## 6 6 28 NA 14.9 66
## 7 7 23 299 8.6 65
## 8 8 19 99 13.8 59
## 9 9 8 19 20.1 61
## 10 10 NA 194 8.6 69
## # ℹ 21 more rows- 네 변수들의 평균을 다음의 형태로 출력해 보자. 평균값이
NA로 나온 변수가 있는 이유는 무엇인가?
## Ozone Solar.R Wind Temp
## NA NA 11.62258 65.54839- 변수의 평균값이
NA가 되지 않도록 조치해서 다음의 형태로 다시 출력해 보자.
## Ozone Solar.R Wind Temp
## 23.61538 181.29630 11.62258 65.54839변수
Ozone과Solor.R의 결측값이 있는 행은 모두 제거하고, 그 결과를airs_1에 할당하라.airs_1의 변수Ozone이 평균값 이상인 그룹과 평균값 미만인 그룹으로 구분해 주는 변수Oz.Gp를 생성해서, 다음과 같이airs_1에 추가하자.
airs_1
## # A tibble: 24 × 6
## Day Ozone Solar.R Wind Temp Oz.Gp
## <dbl> <dbl> <dbl> <dbl> <dbl> <fct>
## 1 1 41 190 7.4 67 High
## 2 2 36 118 8 72 High
## 3 3 12 149 12.6 74 Low
## 4 4 18 313 11.5 62 Low
## 5 7 23 299 8.6 65 Low
## 6 8 19 99 13.8 59 Low
## 7 9 8 19 20.1 61 Low
## 8 12 16 256 9.7 69 Low
## 9 13 11 290 9.2 66 Low
## 10 14 14 274 10.9 68 Low
## # ℹ 14 more rowsairs_1의 변수Oz.Gp의 값이High인 그룹과Low인 그룹에서 변수Solor.R,Wind,Temp의 평균값에 어떤 차이가 있는지 확인하고, 그 효과를 설명해 보자.
5. 웹서버 https://raw.githubusercontent.com/yjyjpark/R-and-statistical-analysis/master/Data/에 있는 파일 cars.csv에는 234대 자동차의 제조회사, 모델, 엔진 기통 수, 변속기 종류, 연비가 입력되어 있다.
- R로 불러와서 다음과 같이 출력해 보자.
cars
## # A tibble: 234 × 5
## manufacturer model cyl trans mpg
## <chr> <chr> <dbl> <chr> <dbl>
## 1 audi a4 4 auto 29
## 2 audi a4 4 manual 29
## 3 audi a4 4 manual 31
## 4 audi a4 4 auto 30
## 5 audi a4 6 auto 26
## 6 audi a4 6 manual 26
## 7 audi a4 6 auto 27
## 8 audi a4 quattro 4 manual 26
## 9 audi a4 quattro 4 auto 25
## 10 audi a4 quattro 4 manual 28
## # ℹ 224 more rows- 변수
manufacturer와model을 변수maker로 통합해 보자. 두 변수 값을 통합할 때 구분자는"-"을 사용하라. 통합 결과는 다음과 같다.
cars
## # A tibble: 234 × 4
## maker cyl trans mpg
## <chr> <dbl> <chr> <dbl>
## 1 audi-a4 4 auto 29
## 2 audi-a4 4 manual 29
## 3 audi-a4 4 manual 31
## 4 audi-a4 4 auto 30
## 5 audi-a4 6 auto 26
## 6 audi-a4 6 manual 26
## 7 audi-a4 6 auto 27
## 8 audi-a4 quattro 4 manual 26
## 9 audi-a4 quattro 4 auto 25
## 10 audi-a4 quattro 4 manual 28
## # ℹ 224 more rows변수
maker의 값이 동일한 자동차가 많이 입력되어 있다. 변수maker에는 몇 종류의 서로 다른 자동차 모델이 입력되어 있는지 확인해 보자.변수
cyl의 값이 4이고trans의 값이"auto"인 자동차의 대수와 변수cyl의 값이 8이고trans의 값이"auto"인 자동차의 대수를 확인하자.변수
cyl의 값이 4이고trans의 값이"auto"인 자동차의 변수mpg의 평균값과 변수cyl의 값이 8이고trans의 값이"auto"인 자동차의 변수mpg의 평균값을 계산하고 비교해 보자.